报告出品方: 国金证券 以下为报告原文节选 ------ 1.数据要素市场是数字经济发展的核心引擎 1.1数据成为生产要素,成为数字经济时代的“石油” 数据要素作为较新的经济学概念,准确清晰地理解和定义数据要素市场相关概念是探索和培育数据要素市场模式和方向的重要前提,根据国家工业信息安全发展研究中心报告,我们给出以下对数据、数据资源和数据资产的定义: 1)数据:是指所有能够输入计算机程序处理、反映一定事实、具有一定意义的符号介质的总称。 2)数据资源:是指按一定规则排列组合的物理符号集合,用于承载或记录信息,这些信息可以是数字、文字、图像,也可以是计算机代码的集合。 3)数据资产:本质上是产权的概念,是指个人或企业拥有或控制的、以物理或电子方式记录的能够为个人或企业带来经济利益的数据资源。 数据已成为新型生产要素,具有劳动工具和劳动对象的双重属性。生产要素是指进行社会生产经营活动所必需的资源和环境条件,随着经济的发展,生产要素的具体形态和主次序列不断变化,传统的生产要素主要包括土地、资本、技术和劳动力,在5G、物联网、云计算、大数据、区块链和人工智能等技术的共同作用下,数据对生产的贡献日益突出。作为新型生产要素,数据具有劳动工具和劳动对象的双重属性,作为劳动对象,数据通过采集、加工、存储、流通和分析等环节具有价值和使用价值,作为劳动工具,数据通过融合应用能够提高生产效率,推动生产力的发展。数据要素市场的目标是实现数据要素的市场化配置,将数据要素从尚未完全由市场配置转向由市场配置的动态过程,其目的是建立以市场为基础的调配机制,实现数据的流动价值或在流动中产生价值。 数据要素主要通过业务贯通、数智决策和流通赋能三条途径实现自身价值。首先,数据投入生产的一次价值体现在支撑企业和政府的业务系统运转,实现业务间的贯通,为释放数据要素的初级价值,政府和企业的主要任务是推进业务的数字化和各类业务信息系统的建设。其次,数据要素二次价值释放体现在通过加工、分析、建模等过程,揭示出更深层次的关系和规律,从而使生产、经营、服务和治理等环节的决策更加智慧、智能和精准,该过程对企业的数据挖掘和分析能力提出了更高的要求。最后,数据要素的三次价值释放体现在将数据流通到更需要它的地方,让不同来源的优质数据在新的业务需求和场景中汇聚和融合,实现双赢和多赢的价值利用。 从产业链的角度出发,我们将数据要素市场归结为数据采集、存储、加工、流通、分析和生态保障六大模块。数据采集环节关注确保数据采集的准确性和全面性。数据存储环节关注确保数据存储的安全性和实时调用的可行性。数据加工环节关注确保数据加工的精度和准确性。数据流通环节是数据要素市场的核心环节,关注在保障所有者权利的前提下进行合理合规的数据流通。数据分析环节关注深度分析和挖掘数据的价值和潜力。生态保障环节包括数据资产评估、登记结算、交易撮合、争议仲裁以及跨境流动监管等,旨在为数据要素市场各主体提供有效的保障,并构建一个良好的市场生态。 数据要素产业图谱清晰,国内企业集中度较高。虽然数据要素作为一个较新的经济学概念,但与数据相关的产业已经在国内经过了较长时间的发展,例如在数据存储方面信创之风已经提前带领国内数据库反弹复苏,以华为、阿里和腾讯为首的云数据库,以及以达梦、南大通用为首的传统数据库,还有 OceanBase、GoldnDB 和 TiDB 等国内分布式交易型数据库快速发展。除此之外,AI 大模型的快速崛起也大幅增加了对模型训练的需求,数据加工中的数据清洗、标注和审核等工作需求激增,百度 EasyData、海康 NLP 等技术获得关注。 数据流通环节作为二级市场的关键环节,在数据确权和隐私计算方面的国内企业如拓尔思、易华录等公司获得市场资金大幅支持。生态保障的主要参与者是政府机构和组织,例如北京数据资产评估中心、大数据交易所以及国家数据局等监管机构等。 我国数据要素市场规模持续扩张,数据要素成为数字经济发展新引擎。数字化的本质是在信息化的基础上,对系统产生的数据要素,利用大数据、AI、区块链等数字技术,进行流程改造、数据决策、商业模式重构等全新的价值开发,核心目的是实现商业增量。国家工业信息安全发展研究中心数据显示,我国 2021 年数据要素市场规模达 815 亿元,预计“十四五”发展期间年均增长率达 25%,有望在 2025 年达到 1,990 亿元的市场规模。同时可以发现,2022 年我国数据要素市场中数据存储、分析和加工行业位列前三,随着人工智能和互联网技术的进步,数据量的增大对数据存储提出了更高要求,数据的安全、可靠和隐私存储市场需求逐步扩张,AI 大模型的快速演进带动数据加工中的清洗和标注工作需求量激增,我们看好数据要素行业相关企业未来的快速发展。 1.2 政策催化强劲,行业景气度拐点已至 从政策到顶层管理架构,数据要素体系根基逐渐稳固。2019 年党的十九届四中全会首次将数据列为生产要素,表明国家大力发展数字经济的决心,并标志着数据从资源向要素的转变。2020 年 4 月,中共中央、国务院发布了《关于构建更加完善的要素市场化配置体制机制的意见》,明确将数据市场与土地市场、劳动力市场、资本市场和技术市场列为加快培育的五大核心生产要素市场之一,数据要素进入市场化阶段。2022 年 12 月,国务院发布“数据二十条”这一纲领性文件,确立了数据要素发展顶层指导框架。2023 年 3 月,国家数据局成立,负责协调推进数据基础制度建设,统筹数据资源整合共享和开发利用,统筹推进数字中国、数字经济、数字社会规划和建设等。地方层面,多个省市密集发布数据要素相关政策,数据要素产业进入实质性落地阶段。 顶层文件“数据二十条”搭建数据要素“四梁八柱”。2022 年 12 月 19 日,《中共中央国务院关于构建数据基础制度更好发挥数据要素作用的意见》正式对外发布,又称“数据二十条”,这是继 2020 年 4 月 10 日发布的《中共中央国务院关于构建更加完善的要素市场化配置体制机制的意见》之后首次全面明确国家级政策文件中的数据基础制度。“数据二十条”涵盖了四个制度领域,包括数据产权、流通交易、收益分配和安全治理。在数据产权方面,建立数据资源持有权、数据加工使用权和数据产品经营权的“三权分置”结构。 在流通交易环节,建立场内外结合的数据要素流通和交易制度。在收益分配方面,遵循了“谁投入、谁贡献、谁受益”的原则。在实行贡献值分配的基础上,还关注公益和相对弱势群体的利益,在再分配环节进行相应的考虑。在安全治理方面,通过“以链治数”的监管模式,实现了数据要素的安全可信流通。“数据二十条”的发布对于更好地发挥数据要素的作用具有重要意义,为数据基础制度的建设提供了全面的指导和规范。 国家数据局获批成立,职责权限明晰集中有望实现数据要素发展再提速。2023 年 3 月,《党和国家机构改革方案》印发,该方案在保持现有工作格局的总体稳定的前提下,提出了整合共享和开发利用数据资源的职责相对集中的要求。根据该方案,国家数据局作为国家发展和改革委员会管理的国家局,负责协调推进数据基础制度建设,统筹推进数字中国、数字经济、数字社会规划和建设等任务。我国数字经济规模全球排名第二,约占国内经济总量的 40%左右,设立国家数据局展示了与时俱进的态度,体现了国家对数字经济发展的顶层设计,符合时代要求和发展需求。国家数据局由发展和改革委员会直接管理,有助于消除部门之间、系统之间和地区之间的壁垒,实现数据要素的互联互通,将解决过去数字经济管理中的碎片化问题,并减少地方数字经济发展不均带来的数字鸿沟,提高数据交换的效率和准确性,加快数据要素产业的发展进程。 多个省市成立数据集团,有望成为各地政府参与数据运营的抓手。央企层面,中国电子数据产业集团于2022年12月成立,是国内首家由中央企业设立的数据产业集团;地方层面,上海、河南、福建、陕西、成都、南京等地陆续成立数据集团,多为政府主导。数据集团以数据为核心业务,实现公共数据、行业数据和社会数据的交汇、供给、配置及市场化开发利用,开展数字资产运营、数据交易服务和数字产业投资。 各地大数据交易所陆续挂牌运营,加速数据要素价值转化。我国自 2014 年开始探索建立类似证券交易所形式的数据交易机构,随着数据要素相关政策的推动,数据产品交易迎来2.0 时代。2015 年 4 月,贵阳大数据交易所正式挂牌,根据数据交易网,截至 2023 年 6月 21 日,贵数所已累计集聚“数据商”、“数据中介”等市场主体 629 家,上架产品 1055个,交易 888 笔,共计交易额达 14443 万元。2021 年 11 月,上海数据交易所揭牌交易,根据数据交易网,2022 年上海数据交易所数据产品挂牌超 800 个,涉及金融、交通、工业、通信等 12 个行业领域,交易金额突破 1 亿元。2022 年 11 月,深圳数据交易所挂牌运营,截至 2023 年 6 月,深数所已累计交易突破 700 笔,覆盖 165 个应用场景,生态合作机构突破 900 家,汇集数据产品超 1500 个,服务触达 2000 家以上市场主体。截至 2022年底,全国数据交易所已近 50 家。各大数据交易所交易主题、上架产品以及交易规模都处于快速发展态势,数据产品和服务类型日益丰富,能够提供数据 API、数据集、数据报告等多种形式的产品和服务。 土地财政收入增速下降,数据要素探索“数据财政”可能性。土地财政主要指政府通过出售土地或者收取土地使用权等方式获取财政收入的政策,然而土地资源的有限性在我国经济转型升级和高质量发展的背景下,探索通过财政税收工具和手段从数字经济的关键要素中取得一定比重的财政收入,并发挥财政的基础性、支柱性国家治理作用是非常有意义的。 数据财政是基于大数据和人工智能等新兴技术的发展,将数据视为新的财富来源的理念,具体而言数据财政包括数据进入市场之前,在数商组建、数据产品开发、登记等环节的监管伴随的财政活动,以及数据进入市场之后,在数据开发、服务、再生产等过程,通过财税手段实现对数据市场的激励和管理。欧洲地区率先对数据服务进行征税,在国际税收改革背景下提出的一种对数字服务进行征税的新模式,主要针对的是那些利润丰厚但却往往在欧洲本土纳税不多的跨国数字巨头,给我国推行数据财政提供了参考意义。 “数据财政”制度将在数字经济发展和国家治理中扮演重要角色。数据资源具有公共性,数据权利分置创新拓宽了数据流通空间,建立数据财政制度是完善数据基础制度的需求,体现数字经济公共利益和全民共享数字经济红利;同时,数据财政发挥现代国家治理中财政作用,推动数据要素成为新生产要素,创造良好环境实现要素市场化配置,注入新时代寓意。数据财政主要通过财政支出和收入发挥治理数据要素市场的功能,在数据市场化起步阶段应当以财政激励和适当轻税推动数据供需市场发展,并力争形成良性循环;同时确立数据财政方式和手段,包括归并公共数据、提供公益性服务和有偿服务、采用财税政策和管理要求等;此外,建立数据财政制度和政策,涵盖公共数据资产管理、数据定价、数据税收、收入分配等也是试试数据财政的主要工作之一;最后,运营包括主体准入、运营级次选择、运营体系、税费征管等。 由单一强调“土地财政”转向“土地财政+数据财政”双轨并行。相较于土地财政,数据财政的核心标的从土地转变为数据,从而利用虚拟性、共享性和异质性等特点,排除了土地资源有限、主体独有不可共享和边际效应等问题。在财政收入方面,数据资源的资产性让其能够参与抵押活动,同时主要的收入来源变成了数据授权或出售过程中的收入,参考欧洲地区的数据服务税,还可在数据流通、交易和服务等环节征税。从“土地财政”到“土地财政+数据财政”双轨并行,这种转变反映了政府财政模式的演进和创新,不仅能有效避免单一依赖土地财政的风险,还能充分利用数据资源,增加财政收入的多样性,进一步推动社会经济的发展;同时数据财政也可以为政府提供更准确的数据支持,帮助政府更好地进行政策决策和提供公共服务。 2.垂类 AI 大模型加速落地,推动数据要素市场发展 2.1 AI 大模型向行业垂类模型落地演进,数据成为核心壁垒 2017 年谷歌发布的 Transformer 网络结构是大模型发展的源头技术,自此以后大模型技术在自然语言理解、计算机视觉、智能语音等方面都取得了标志性的技术突破,在模型精度、通用性和泛化能力等方面都实现了跨越式发展。中国自 2020 年进入大模型快速发展期,目前与美国保持同步增长态势,涌现出 GLM、盘古、悟道、文心一言、通义千问、星火认知等一批具有行业影响力的预训练大模型,形成了紧跟世界前沿的大模型技术群。 数据贯穿 AI 垂类模型训练的始终。AI 垂类模型强调领域的 know-how,对数据在深度和质量上的要求更高,模型训练分为四个阶段: 1) 通用预训练:在数据质量有保证的前提下,增加数据的数量和多样性,同时提升模型复杂度,这样可以提供普遍有效的模型增强能力。 2) 领域预训练:在第一阶段通用模型基础上,分别用各个领域数据,再分别做一次预训练,得到适合解决各个不同领域的预训练模型。 3) 任务预训练:选择任务适配的领域预训练模型,在这个模型的基础上,用手头数据,抛掉数据标签,再做一次预训练。 4) 任务 Fine-tuning。 增加训练数据量对模型性能提升来说更具性价比。根据 OpenAI 的研究,独立增加训练数据量、模型参数规模、训练计算量时,预训练模型在测试集上的损失会单调降低,模型的效果越好。DeepMind 在设计 Chinchilla 模型时,对标数据量 300B、模型参数量 280B 的Gopher 模型,选择将参数降低为 Gopher 的四分之一的同时增加 4 倍的训练数据,无论是预训练指标,还是很多下游任务,Chinchilla 的效果都要优于规模更大的 Gopher。 金融垂类数据对于 BloombergGPT 模型性能提升效果明显。Bloomberg 作为全球商业、金融信息和财经资讯的领先提供商,拥有 40 年金融数据的积累。BloombergGPT 是一个有 500亿参数、基于 BLOOM 模型的 LLM,其训练所用的金融数据集包含新闻、档案、网络爬取的新闻稿件、英文财经文档等英文金融文档,共包含 3630 亿个 token,是目前最大的金融数据集。BloombergGPT 在金融语料上的 bits per byte 指标均好于其他垂类模型,在大多数任务中的得分位列第一,是目前最出色的金融垂类模型。 --- 报告摘录结束 更多内容请阅读报告原文 --- 报告合集专题一览 X 由【报告派】定期整理更新 (特别说明:本文来源于公开资料,摘录内容仅供参考,不构成任何投资建议,如需使用请参阅报告原文。) 科技 / 电子 / 半导体 / 人工智能 | Ai产业 | Ai芯片 | 智能家居 | 智能音箱 | 智能语音 | 智能家电 | 智能照明 | 智能马桶 | 智能终端 | 智能门锁 | 智能手机 | 可穿戴设备 |半导体 | 芯片产业 | 第三代半导体 | 蓝牙 | 晶圆 | 功率半导体 | 5G | GA射频 | IGBT | SIC GA | SIC GAN | 分立器件 | 化合物 | 晶圆 | 封装封测 | 显示器 | LED | OLED | LED封装 | LED芯片 | LED照明 | 柔性折叠屏 | 电子元器件 | 光电子 | 消费电子 | 电子FPC | 电路板 | 集成电路 | 元宇宙 | 区块链 | NFT数字藏品 | 虚拟货币 | 比特币 | 数字货币 | 资产管理 | 保险行业 | 保险科技 | 财产保险 | 大数据 














 ┃ 免责声明:本文版权归原发布机构及作者,如涉及侵权请联系删除。本文仅供参考,如需使用相关信息请参阅报告原文。 ┃ 获取PDF完整版报告下载方式请关注:报告派 |










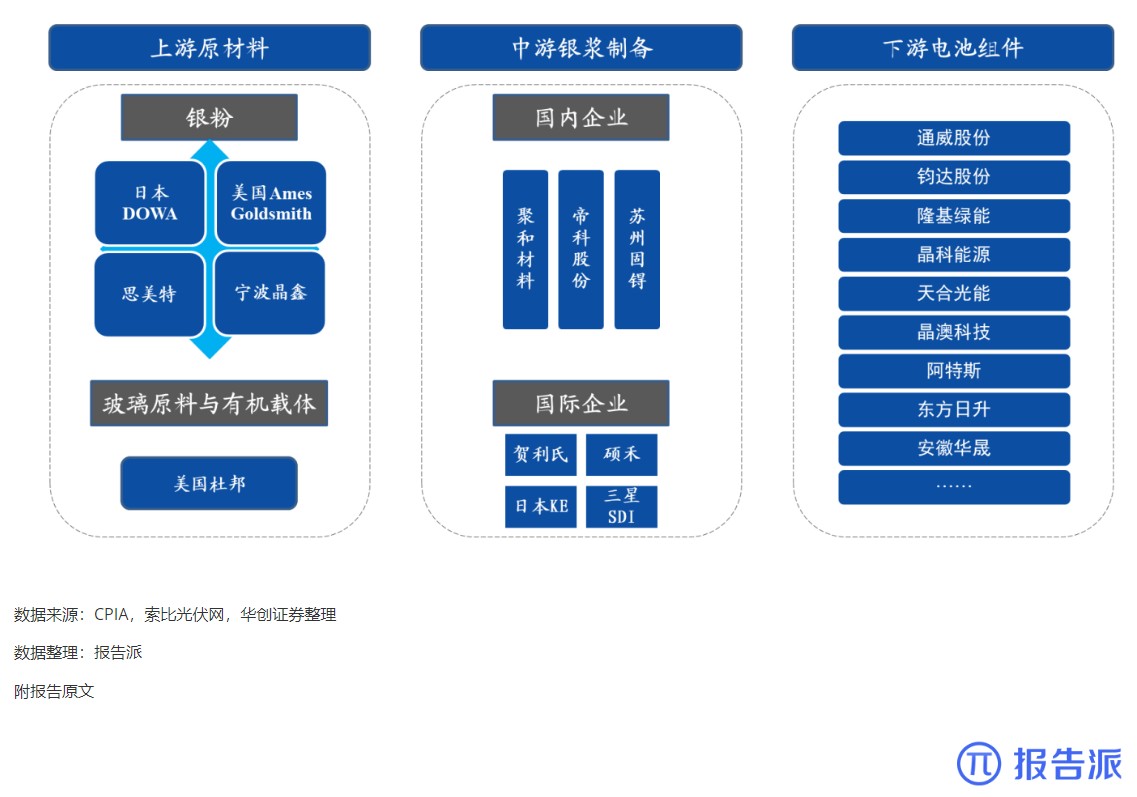
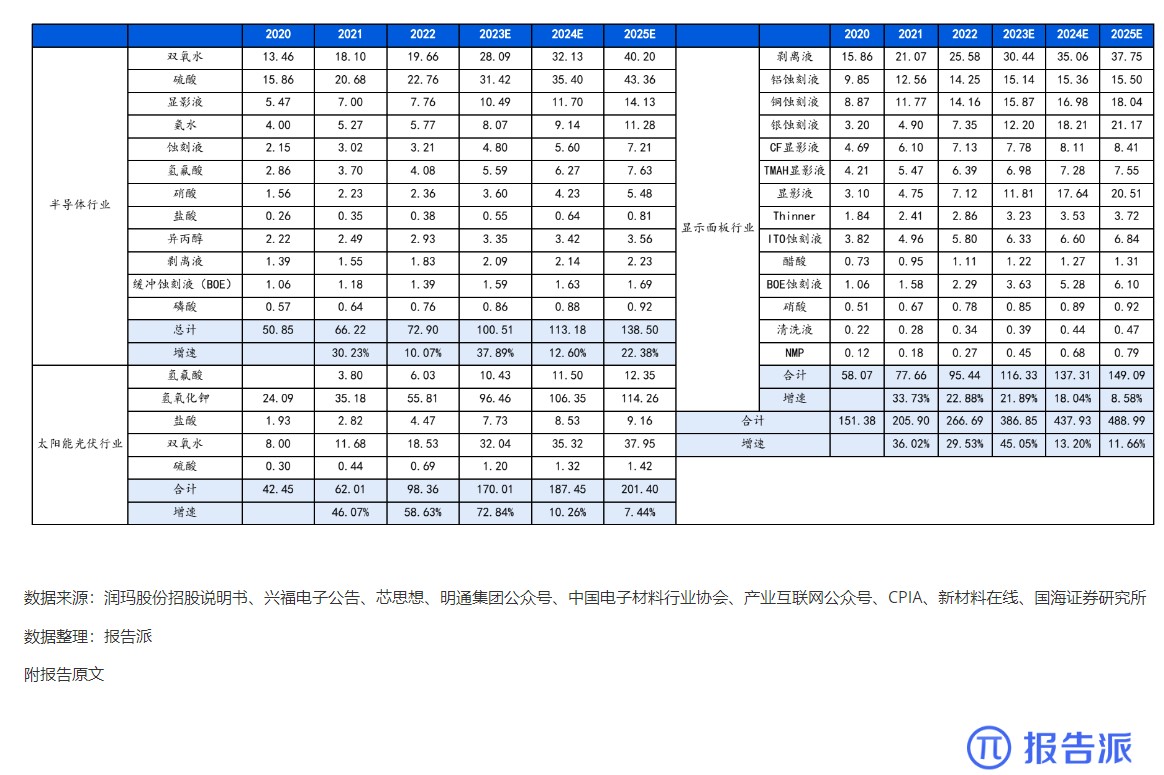
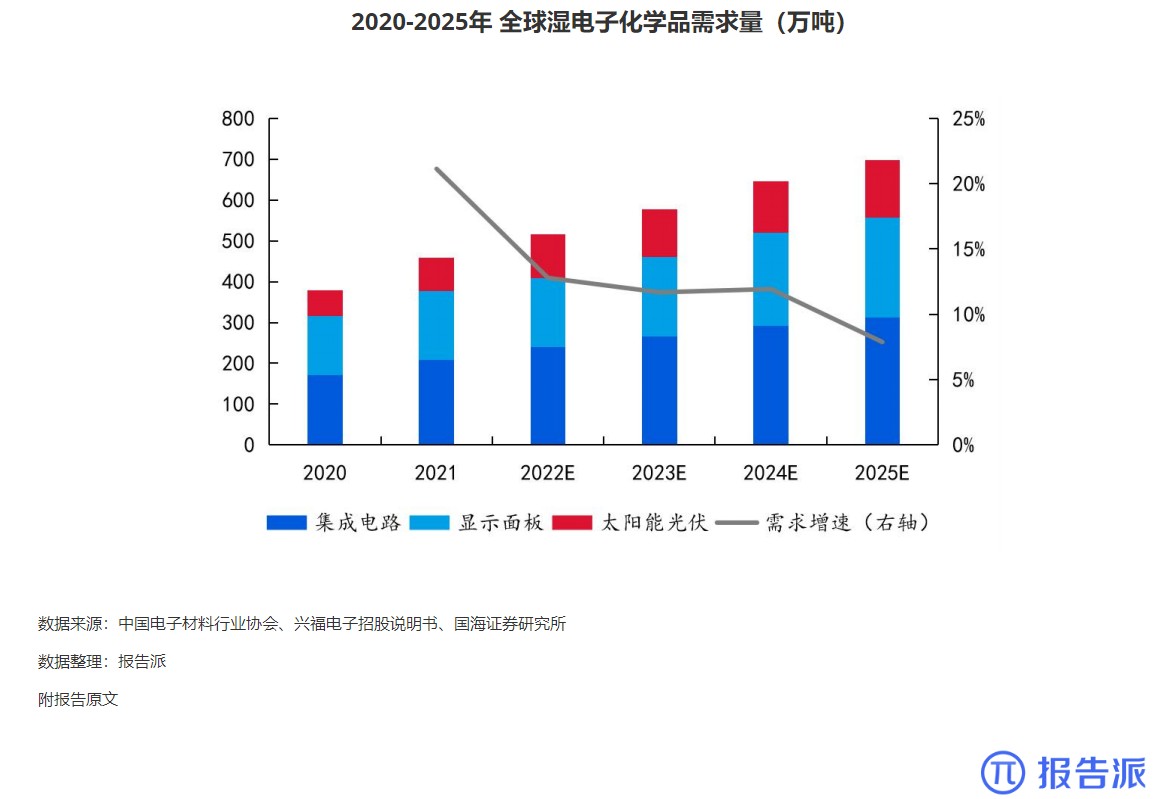
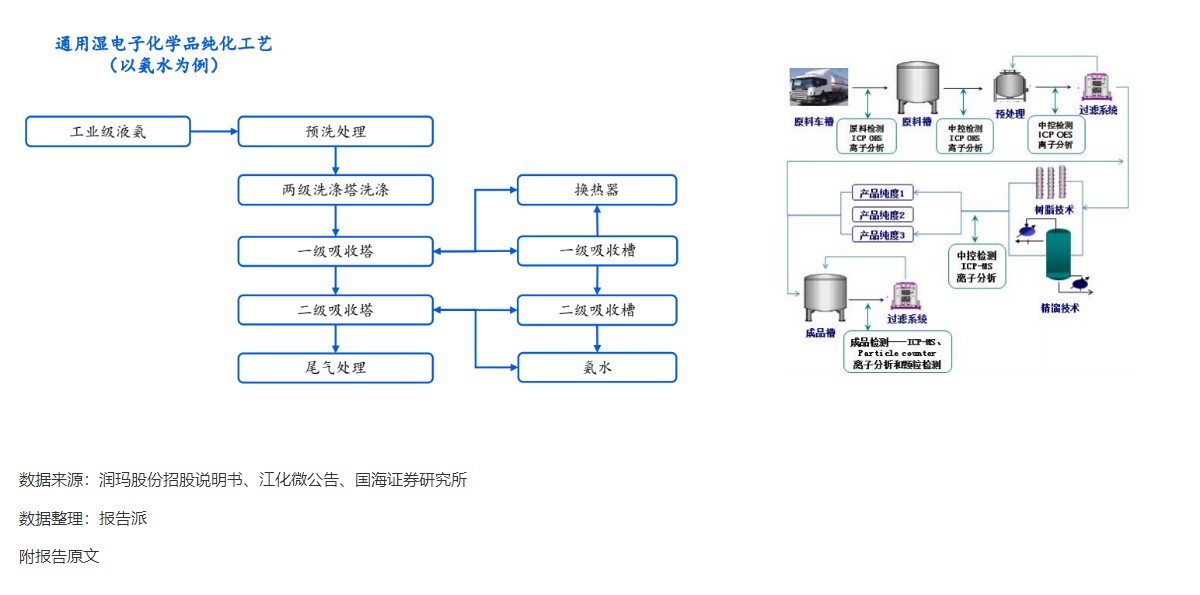
报告派(baogaopai.com)致力于发现互联网资讯,以信息普及传播价值为目的,每日分享热点行业报告、数据图表、精选研读深度报告,致力成为专业的行业研究报告与数据分享平台!
 百度小程序
百度小程序
 访问手机版
访问手机版
 微信公众号
微信公众号
 微信小程序
微信小程序