










2025年基于CXL方案的AI应用研究
摘要: CXL(Compute Express Link)作为一种基于PCIe 5.0的高速互连技术,正在成为破解AI算力与存储瓶颈的关键路径。近日,开放数据中心委员会(ODCC)发布《2025年基于CXL方案的AI应用优化与研究》白皮书,系统探讨了CXL ...
| CXL(Compute Express Link)作为一种基于PCIe 5.0的高速互连技术,正在成为破解AI算力与存储瓶颈的关键路径。 近日,开放数据中心委员会(ODCC)发布《2025年基于CXL方案的AI应用优化与研究》白皮书,系统探讨了CXL技术在MoE、LLM和GNN三大AI场景中的应用潜力与实测性能,为下一代AI数据中心的架构演进提供了权威指引。 CXL技术凭借内存扩展、内存共享和缓存一致性三大能力,打破了传统计算架构中CPU与GPU之间的内存孤岛。 尤其是在AI大模型训练和推理过程中,GPU显存容量有限的问题愈发突出,而CXL通过Type 3设备实现的内存池化,可将系统内存扩展至本地内存的10倍以上。 三星推出的CMM-D、SK海力士的CXL DRAM等产品已进入商用阶段,标志着CXL从实验室走向规模化部署。 在MoE(混合专家模型)场景中,模型参数庞大,推理时面临严重的“内存墙”问题。 白皮书提出首个基于CXL的MoE卸载框架——MoE Offload,利用CMM-D的大容量存储专家参数,并通过计算次序优化、I/O管理、流水线调度和预测性预取四项核心技术,显著降低GPU等待时间。 实测显示,该方案最高可节省82%的GPU内存占用,在内存减少55%的情况下性能损失仅为31%,展现出极高的性价比。 针对大语言模型(LLM)推理中的KV缓存膨胀问题,传统方案依赖SSD卸载,但存在高延迟瓶颈。 本研究构建了基于CXL的多层KV缓存系统,利用CXL内存作为锁页内存池,结合DMA实现低延迟传输。 通过预取优化、多进程并行和存储重叠技术,使数据传输与计算充分重叠。 实验表明,新方案相较旧DRAM方案提升7%,相较无CXL方案性能提升达21%,有效弥合了CXL与本地内存的性能差距。 在图神经网络(GNN)训练中,超大规模图数据常需从SSD加载特征,造成严重I/O瓶颈。 CMM-D GNN方案将图结构与特征数据迁移至CXL内存,并结合NVIDIA的UVA(统一虚拟寻址)技术,实现GPU对CXL内存的直接访问。 测试数据显示,CMM-D方案相较SSD方案训练效率提升8倍,相较传统DRAM方案提升2.5倍,大幅缩短了采样与聚合阶段的等待时间。 综合来看,CXL不仅是硬件层面的升级,更是AI系统架构的范式变革。 它通过统一内存池化,实现了计算资源与存储资源的弹性调度,显著提升了AI训练与推理的能效比。 随着CXL 3.0协议的推进,未来在跨节点内存池化、智能资源调度等方面还将释放更大潜力。 ODCC此次研究为AI基础设施的演进提供了扎实的技术路径,预示着2025年CXL将在AI数据中心迎来规模化落地的关键拐点。 出品方:ODCC 发布时间:2025年 文档页数:55页
|
上一篇:2025年药物政策发展维度报告下一篇:2025年中国人幸福感研究报告
推荐文章

2
2025年云计算行业应用场景报告
资讯
77人已阅读
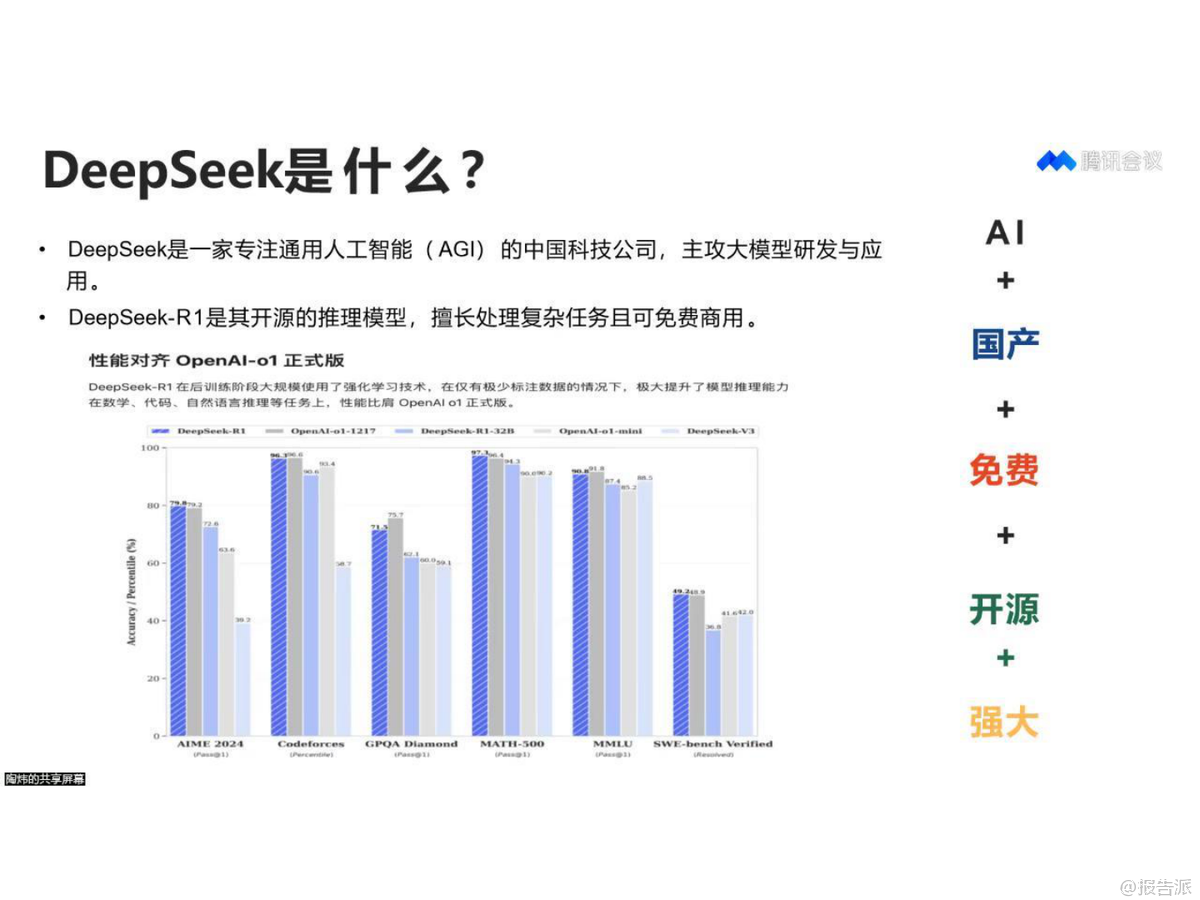
3
2025年文科生AI编程研究报告
资讯
79人已阅读

4
2025年人工智能与进攻性安全研究报告
资讯
82人已阅读

5
2025年数据库行业技术趋势报告
资讯
78人已阅读

6
2025年生成式人工智能商业价值报告
资讯
75人已阅读

7
2025年体育领域政策汇编报告
资讯
75人已阅读
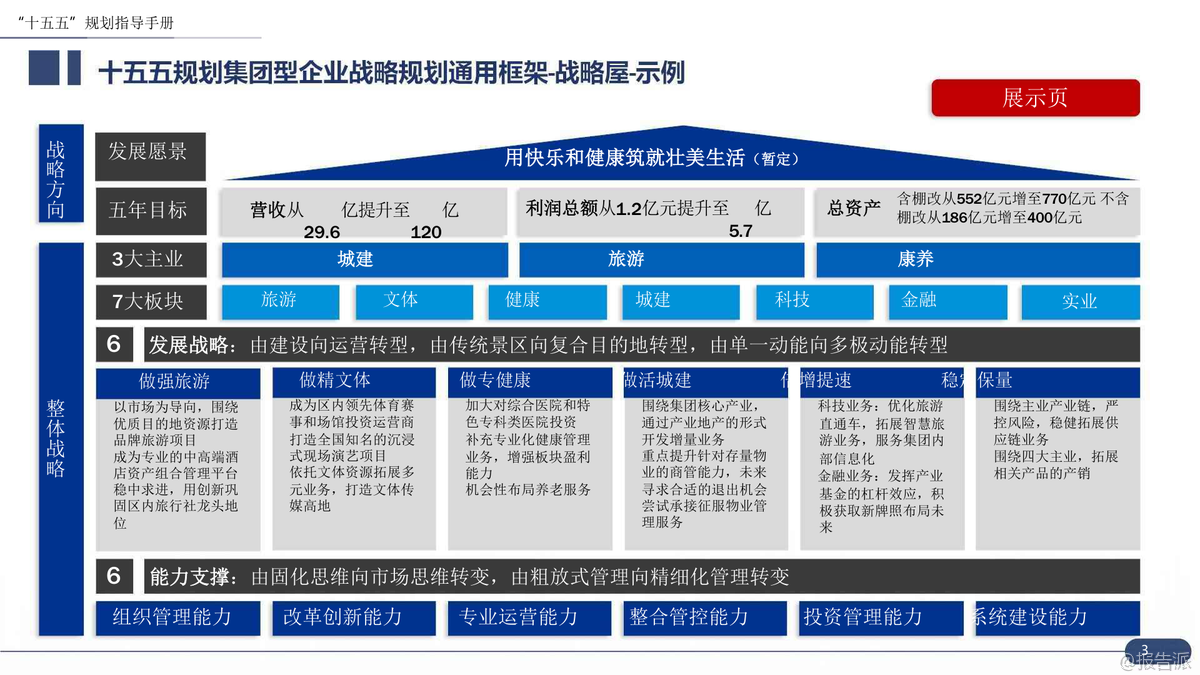
8
2025年大型央国企“十五五”战略规划编制实
资讯
97人已阅读

9
2025年电子元件供应链研究报告
资讯
93人已阅读

10
2024年Web3及金融科技研究报告
资讯
69人已阅读
数据图表
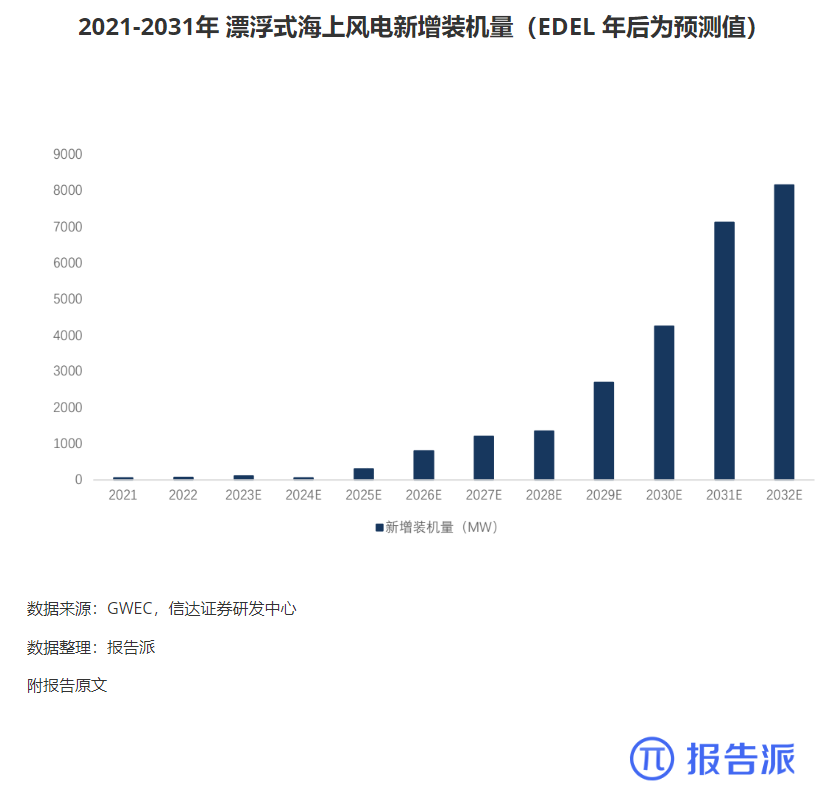

2
2011-2031 年全球海上风电装机量(含预测)
行业数据
1716人已阅读
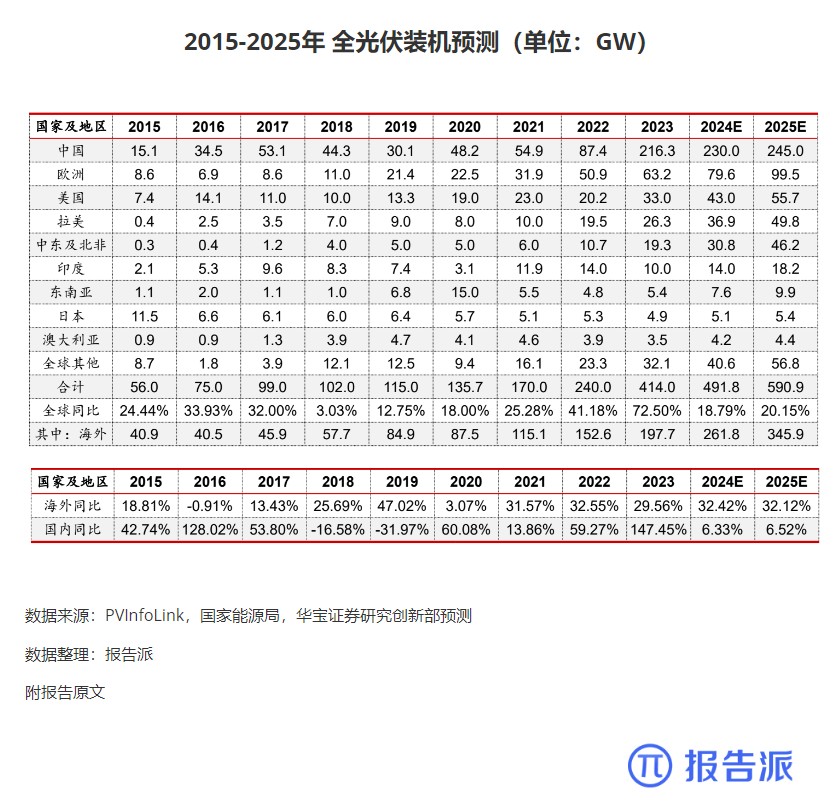
3
2015-2025年 全光伏装机预测(单位:GW)
市场规模
1949人已阅读
4
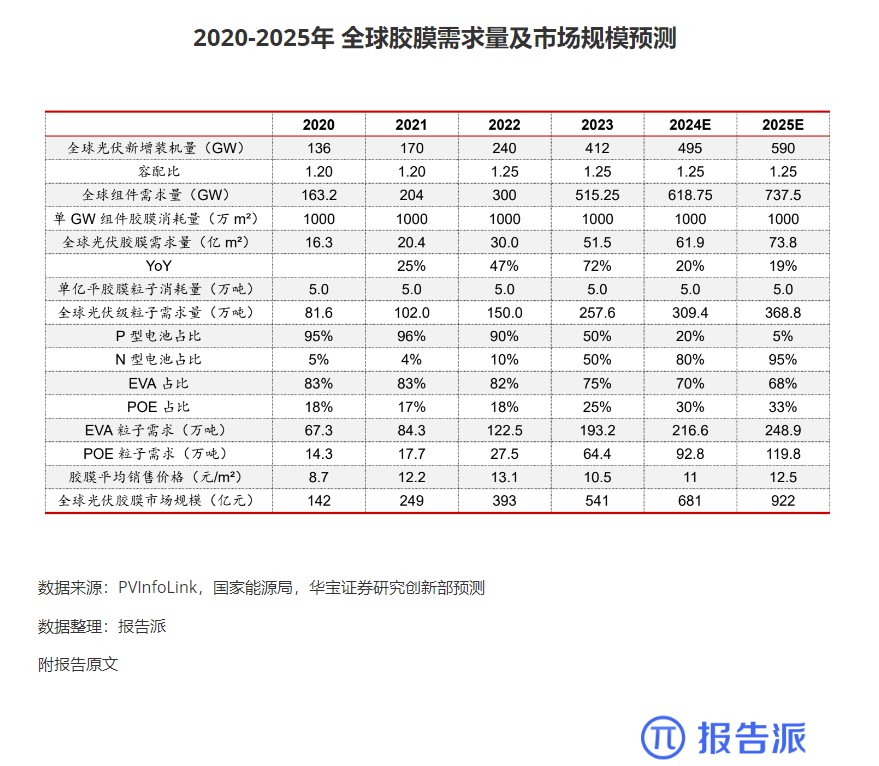
2020-2025年 全球胶膜需求量及市场规模预测
市场规模
1862人已阅读
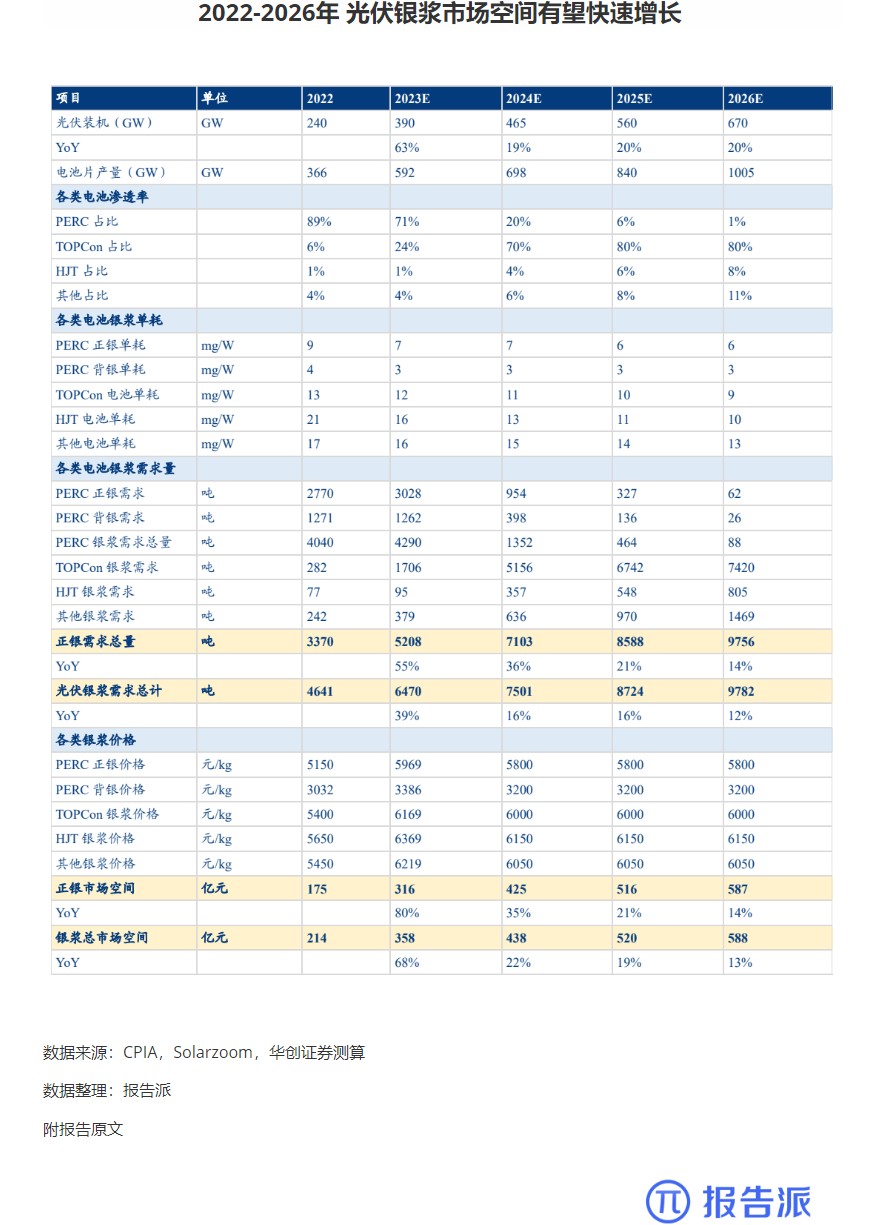
5
2022-2026年 光伏银浆市场空间有望快速增长
市场规模
1932人已阅读
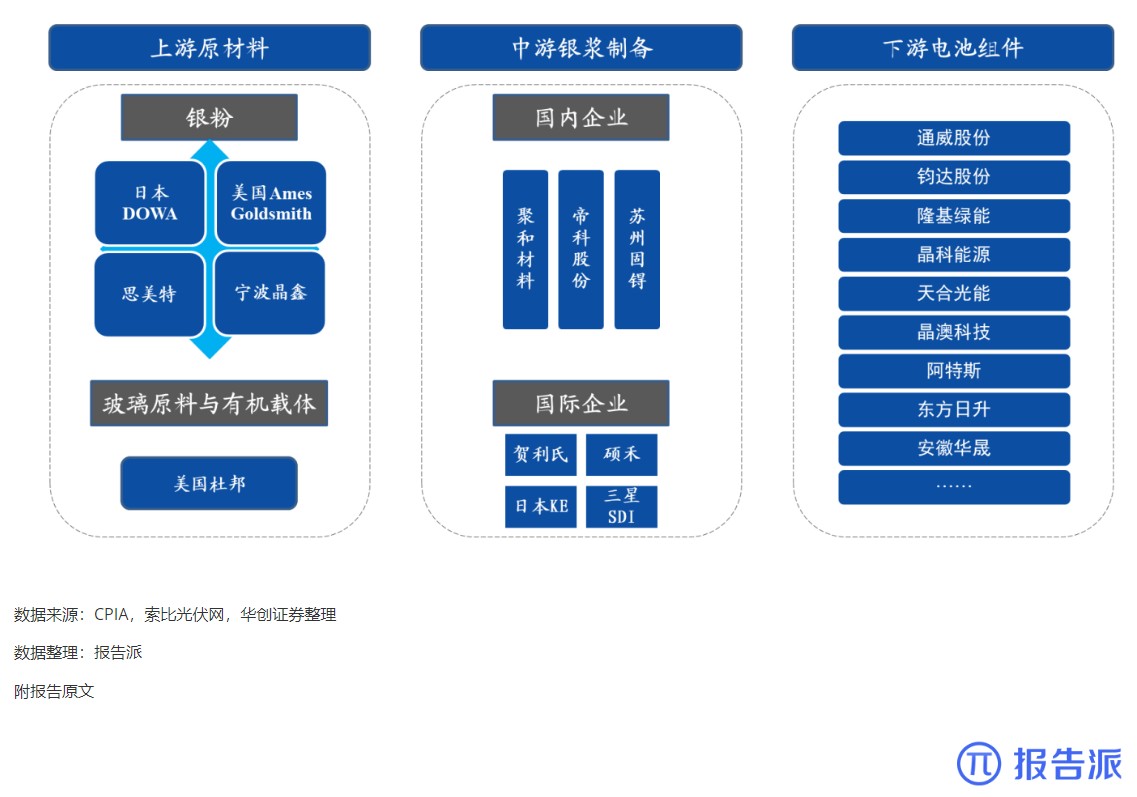
6
光伏银浆产业链相对简单
技术工艺
1828人已阅读
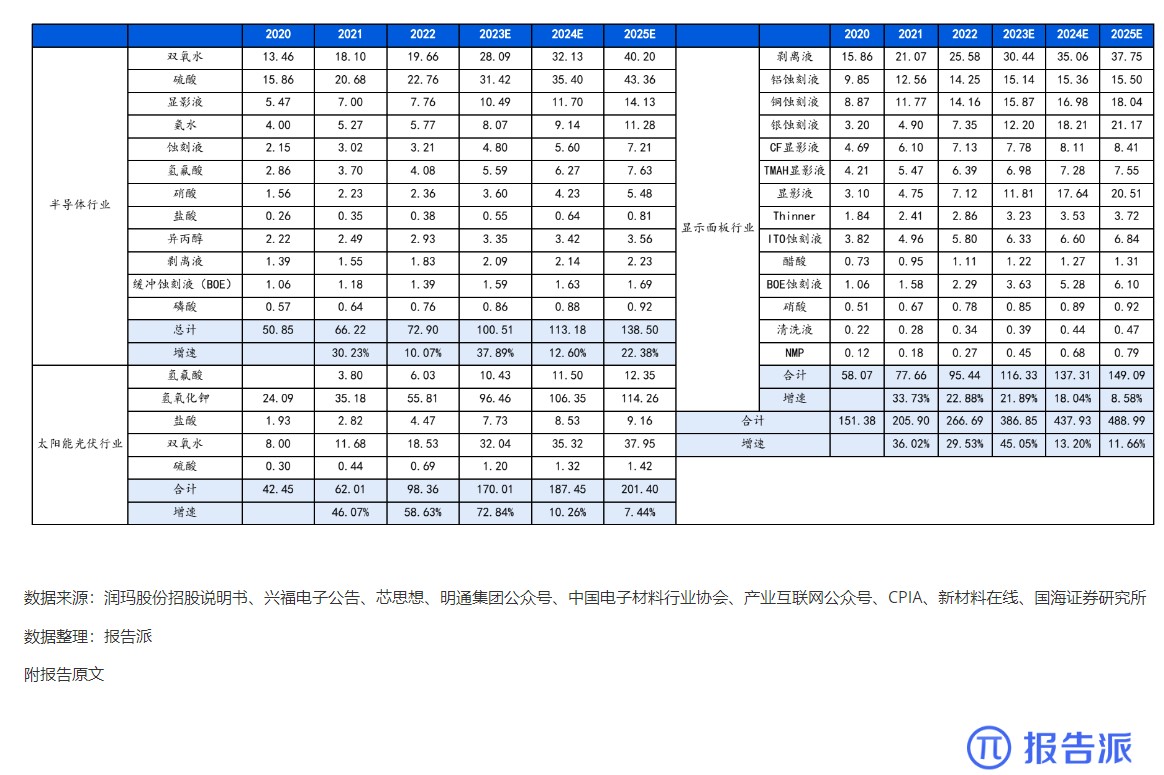
7
2020-2025年 我国湿电子化学品需求预测(万
市场规模
1813人已阅读
8
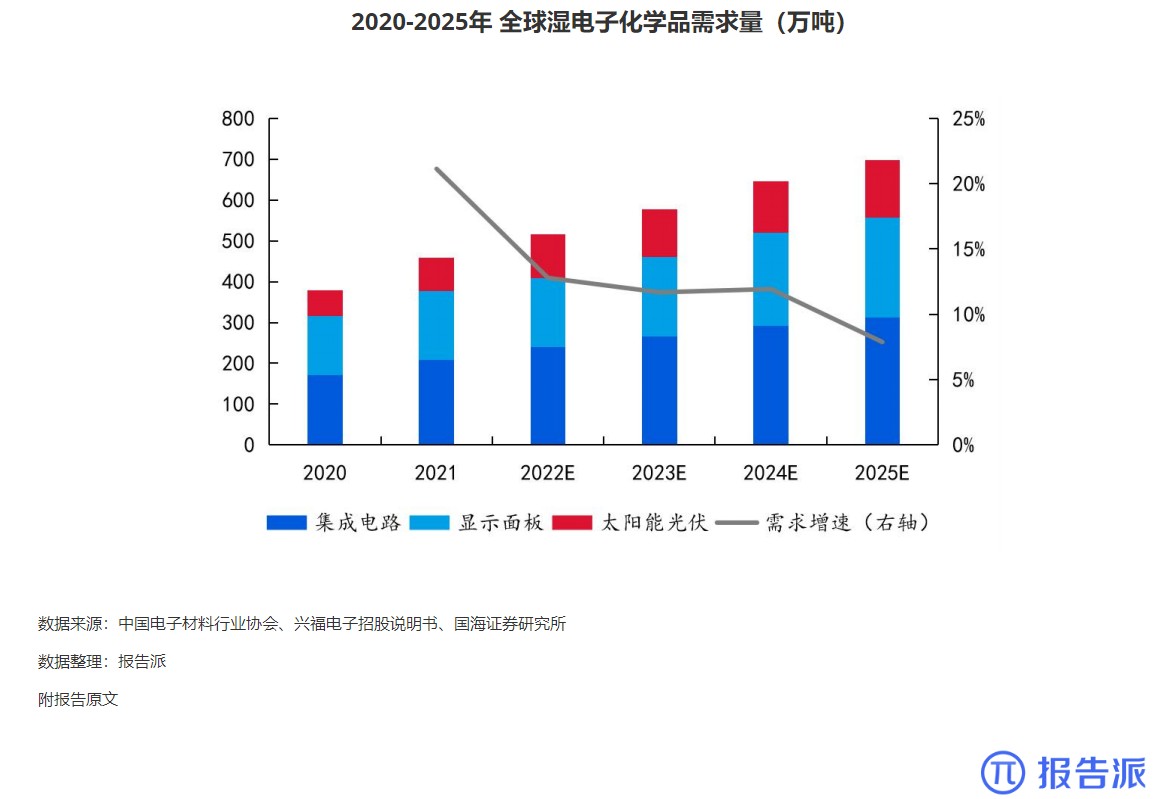
2020-2025年 全球湿电子化学品需求量(万吨
市场规模
1935人已阅读
9
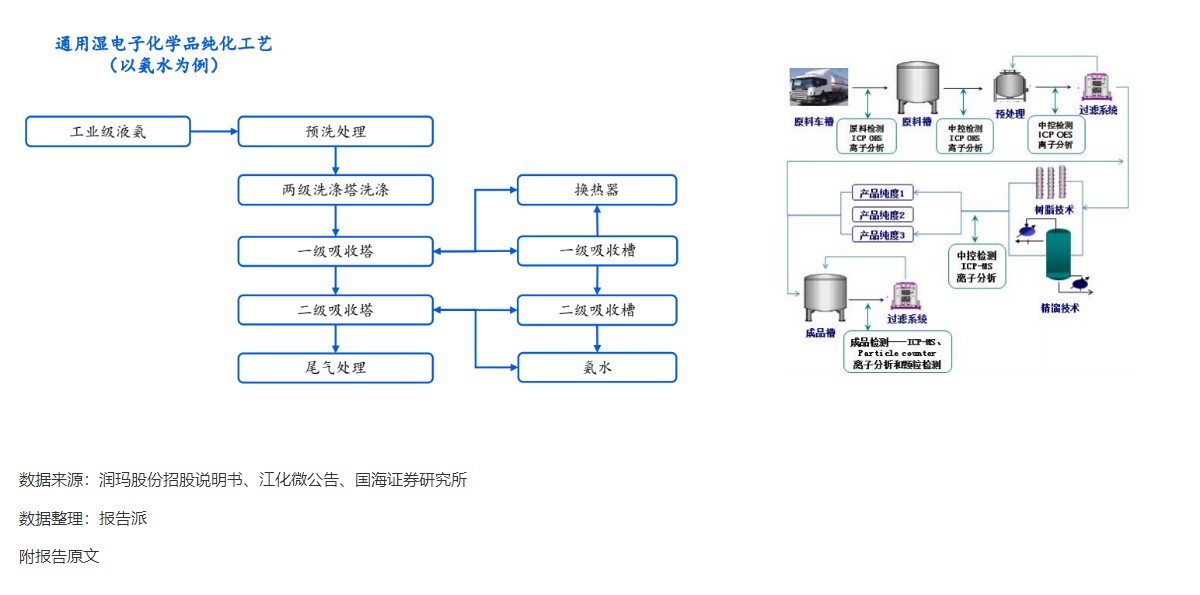
通用湿电子化学品纯化工艺
技术工艺
1674人已阅读
10
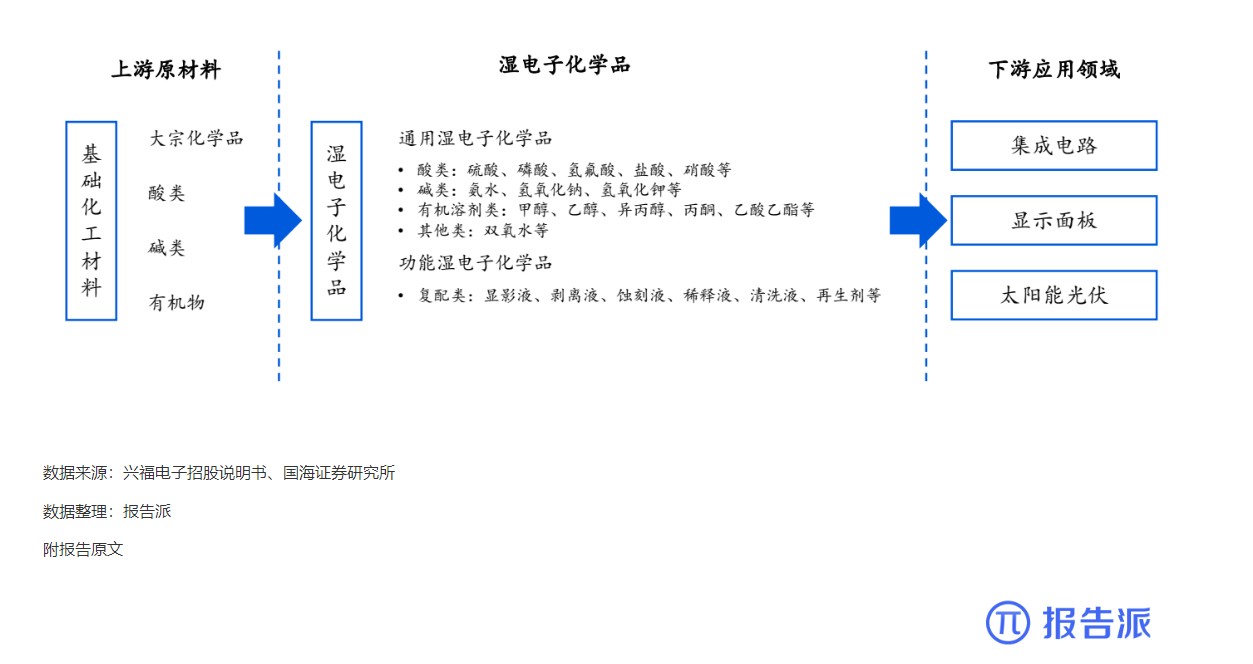
湿电子化学品上下游产业链基本情况
技术工艺
1944人已阅读
热门数据
1
2024年1—2月份规模以上工业增加值增长7.0%
2024-03-22
2
截至2023年底我国累计建成充电基础设施859.
2024-03-22
3
2024年3月21日人民币 NDF 远期合约汇兑美元
2024-03-21
4
2024年1—2月份能源生产情况
2024-03-21
5
2024年2月银行结售汇和银行代客涉外收付款
2024-03-21
6
2024年3月韩国方便面出口2.3万吨,同比增加
2024-03-21



