




报告派研读:2026年人工智能行业深度报告
摘要: 随着生成式人工智能技术的迅猛发展,AI正从辅助工具演进为具备自主认知与社会行为模拟能力的“数字代理人”。清华大学沈阳教授领衔的清新研究团队在《AI模拟社会研究资料1.0版》中系统性地提出了以大语言模型(LLM) ...
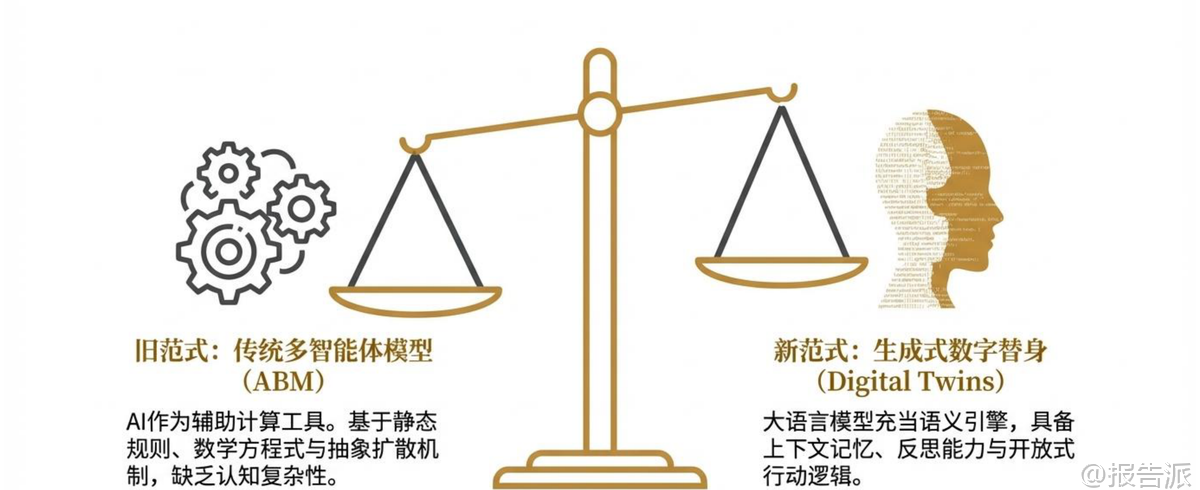
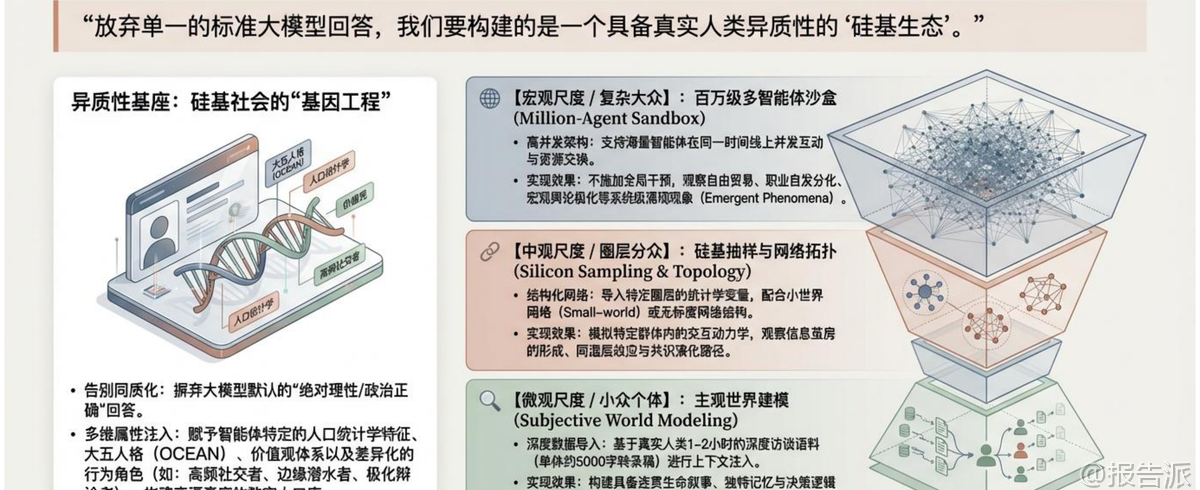
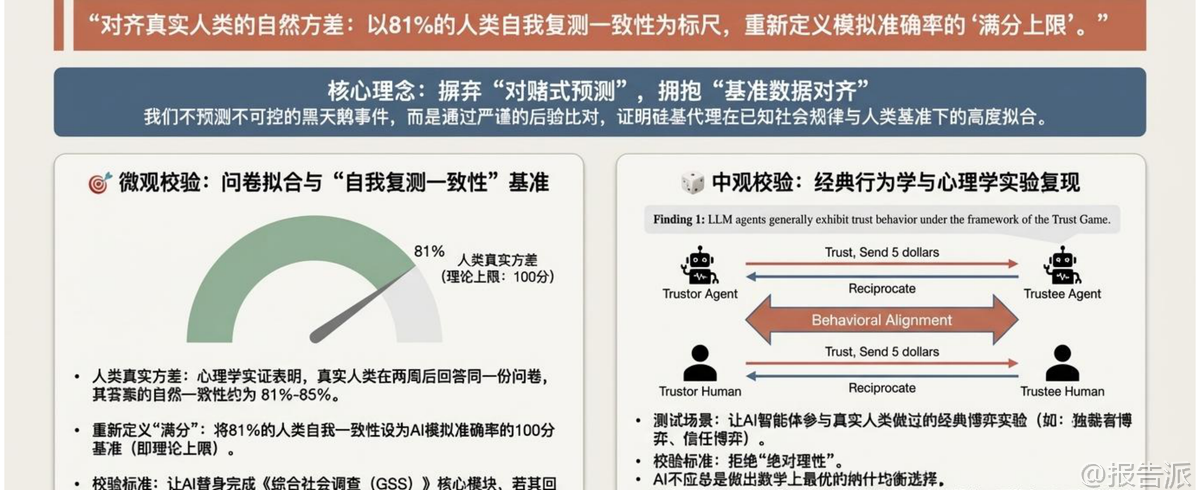
| 随着生成式人工智能技术的迅猛发展,AI正从辅助工具演进为具备自主认知与社会行为模拟能力的“数字代理人”。 清华大学沈阳教授领衔的清新研究团队在《AI模拟社会研究资料1.0版》中系统性地提出了以大语言模型(LLM)驱动的多智能体社会仿真框架,标志着AI在社会科学领域的应用进入新范式。 该报告全面梳理了AI模拟社会的技术架构、科学验证机制、核心应用场景及伦理治理挑战,构建了一个从微观个体到宏观社会的完整研究体系。 报告首先定义了“棘手问题”(Wicked Problems),即现实中难以通过传统试错方式解决的复杂社会议题,如政策制定、极端情境应对和民意演化等。 传统方法受限于高成本、不可逆性和伦理约束,而AI生成式社会模拟则提供了一个安全、可控且高保真的“硅基沙盒”,实现从“辅助计算”到“数字替身”的范式跃迁。 这一转变的核心在于构建具备真实人类异质性的“硅基生态”,而非依赖同质化的大模型输出。 在技术架构层面,报告提出三层演进尺度:宏观尺度支持百万级多智能体并发互动,观察自由贸易、职业分化与系统级涌现现象;中观尺度引入网络拓扑结构,模拟信息茧房、共识液化与群体极化动力学;微观尺度基于深度访谈语料进行主观世界建模,构建拥有连贯生命叙事与独特决策逻辑的“深度数字替身”。 这种分层设计使模拟既具规模又不失细节。 为确保模拟的科学有效性,报告强调建立“科学校验闭环”。 微观层面采用“自我复测一致性”作为基准——人类在两周后重复问卷的一致性约为81%,因此将此设为AI拟合度的“满分上限”;中观层面通过复现经典心理学实验(如信任博弈、独裁者博弈),验证AI是否展现出非理性、互惠等真实人类行为特征;宏观层面则检验系统是否自发涌现出“重尾收益分布”“幂律交往”“财富分层”等“风格化事实”。 最终通过四大“算法逼真度”金标准:社会科学图灵测试、向后连续性、向前连续性和模式对应性,完成全系统可信度评估。 当前实践已从斯坦福“Smallville”小镇的25个智能体扩展至万级甚至百万级社会沙盒。 清华团队开发的AgentSociety平台支持城市级活动仿真,OASIS专注于社交媒体中的信息瀑布与回音壁效应,而MASS框架则以语言原生机制实现可追溯的政策推演。 典型案例包括成功复现Card-Krueger最低工资自然实验,在薪资上涨$0.65/小时情况下未引发显著失业,证明平台具有高度外部效度。 在垂直领域,“AI医院”项目实现了医疗全流程闭环仿真,覆盖发病、分诊、诊断到随访九大节点,虚拟医生通过海量试错实现自进化,并在医学考试中取得93.06%的准确率,推动“紫荆智康”等创业转化落地。 此外,硅基样本正掀起社会调查革命,能快速生成高保真问卷回应,处理167份访谈转录本节省30%-55%时间成本,但同时也带来“合成受访者”对传统民调的真实性冲击。 然而,技术狂奔背后潜藏深刻风险。 报告警示“认知恐怖谷”:AI虽语言流畅,却可能掩盖内在逻辑缺陷,陷入“随机鹦鹉”或“和谐合唱”陷阱。 更严峻的是“反身性危机”——当AI预测被用于政策决策时,会改变现实行为本身,形成“自我实现的预言”,如预测性警务导致过度巡逻,福利稽核制造虚假欺诈证据。 荷兰SyRI案即因算法黑箱侵犯隐私权被判违宪。 文化层面,“模型崩溃”正在发生:递归训练使合成数据反哺模型,长尾消失、低频差异被抹除,导致文化同质化与思想扁平化。 AI成为罗兰·巴特意义上的“终极神话制造者”,将统计规律包装为自然常识。 认识论上,“文本连贯性≠真实意愿”,合成意见可轻易污染公共咨询,动摇民主治理根基。 为此,报告呼吁建立全球合规框架:遵循GDPR最小数据原则,实施动态知情同意;落实《欧盟AI法案》强制披露义务,防止深度伪造误导;在中国则需严格执行网信办关于生成内容标识的规定。 哲学层面指出,AI社会模拟本质是“文本化合法性”对“肉身经验残差”的逼近——它能重演制度规则与语言游戏,却无法感受真实世界的重量与痛感。 最终定位应是将AI视为“策略探索器”与“机制测试床”,而非替代人类田野的终极答案。 必须坚守方法底线:保留肉身经验的最终解释权,警惕将连贯文本误作客观证据。 正如报告结语所言:“AI对社会的模拟是一场无比逼真的语言游戏,它完美重演了人类编织的意义之网,却永远无法跨越那道界限,去感受网中之人的重量。 ” 本文由【报告派】研读,输出观点仅作为行业分析! 原文标题:原文标题:2026-03-10-清新研究-人工智能行业:AI模拟社会研究资料1.0版 发布时间:2026年 出品方:清新研究
精品报告来源:报告派 |
推荐文章

2
2025年云计算行业应用场景报告
资讯
100人已阅读
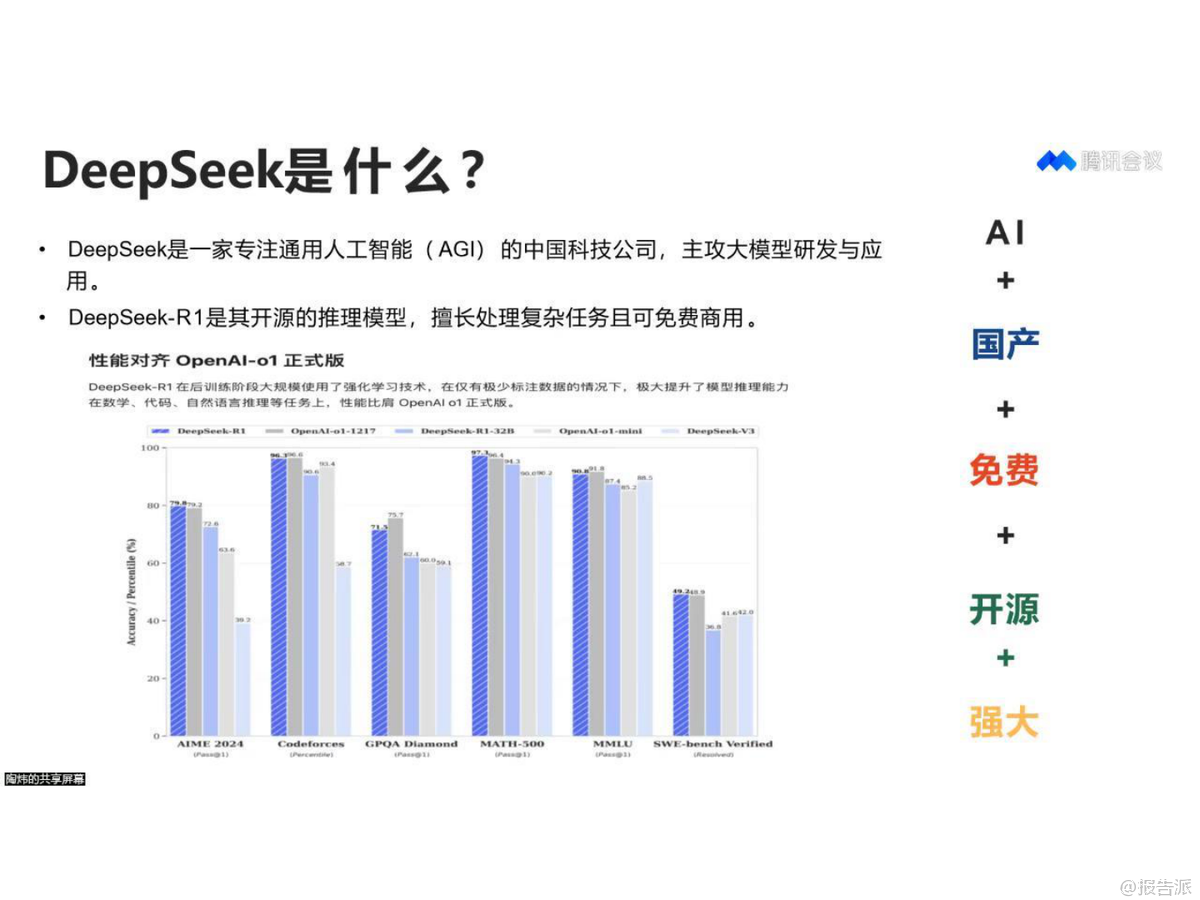
3
2025年文科生AI编程研究报告
资讯
107人已阅读

4
2025年人工智能与进攻性安全研究报告
资讯
103人已阅读

5
2025年数据库行业技术趋势报告
资讯
101人已阅读

6
2025年生成式人工智能商业价值报告
资讯
100人已阅读

7
2025年体育领域政策汇编报告
资讯
95人已阅读
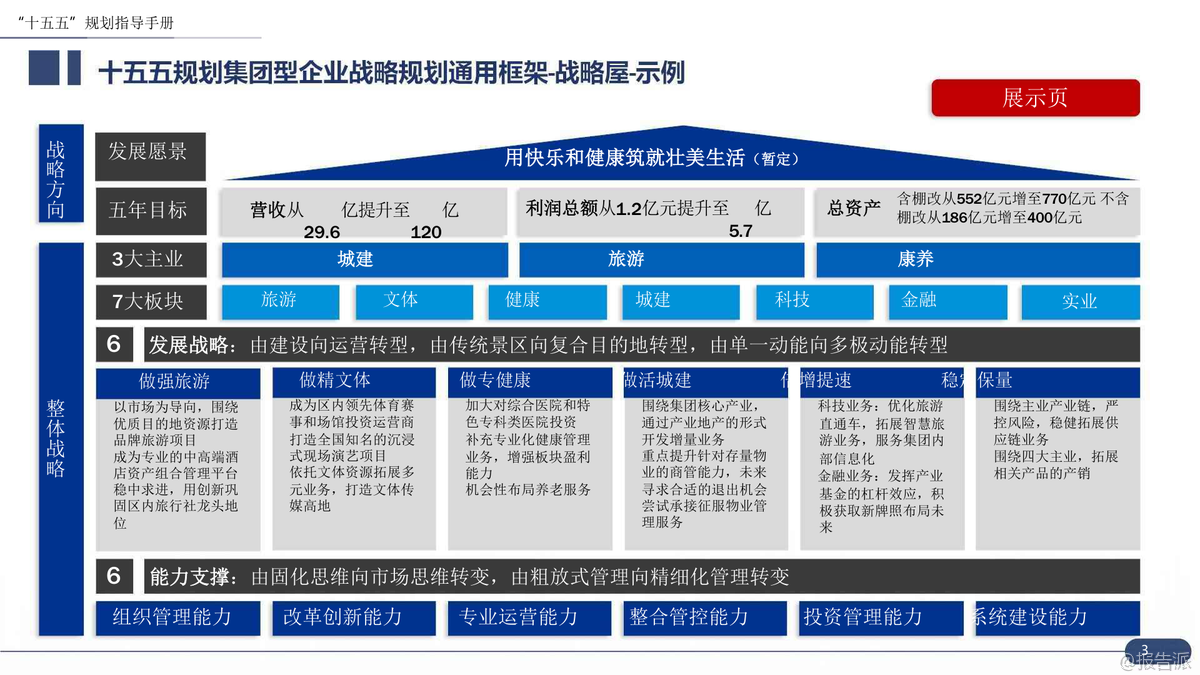
8
2025年大型央国企“十五五”战略规划编制实
资讯
123人已阅读

9
2025年电子元件供应链研究报告
资讯
114人已阅读

10
2024年Web3及金融科技研究报告
资讯
88人已阅读
数据图表
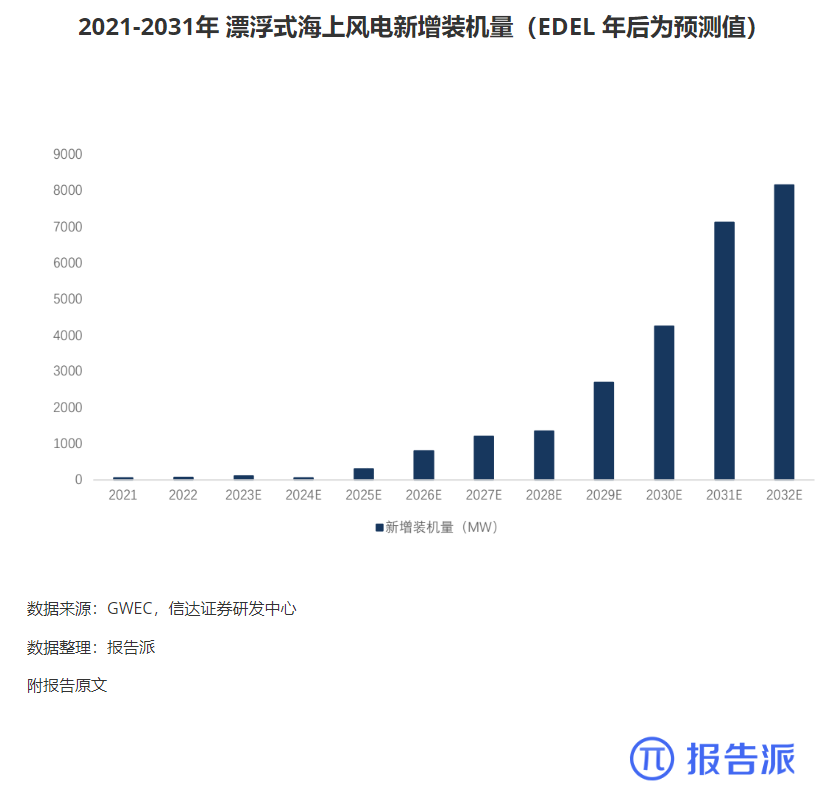

2
2011-2031 年全球海上风电装机量(含预测)
行业数据
1725人已阅读
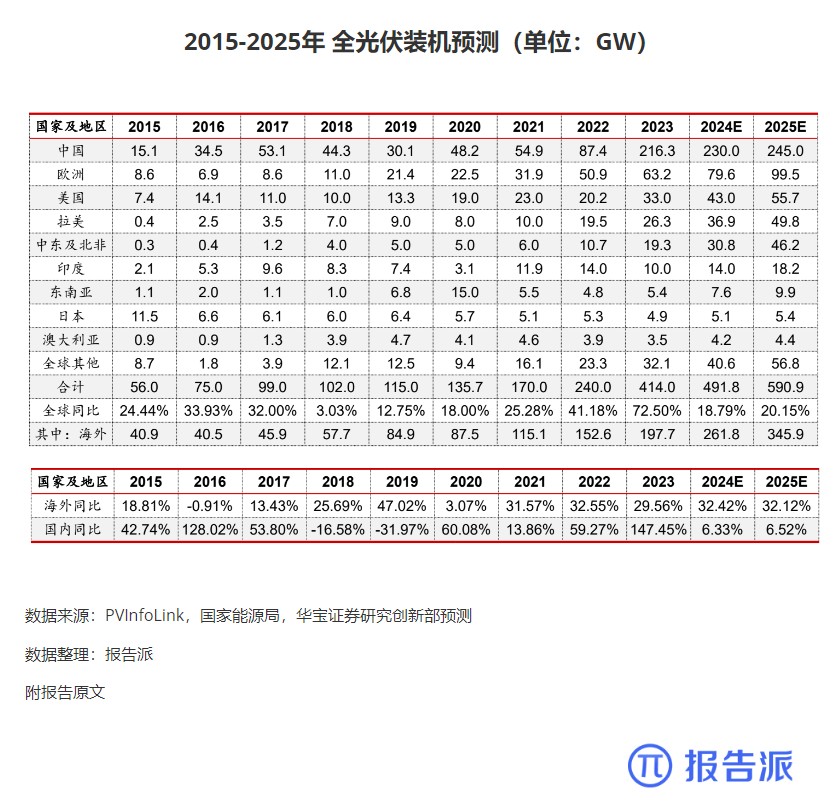
3
2015-2025年 全光伏装机预测(单位:GW)
市场规模
1960人已阅读
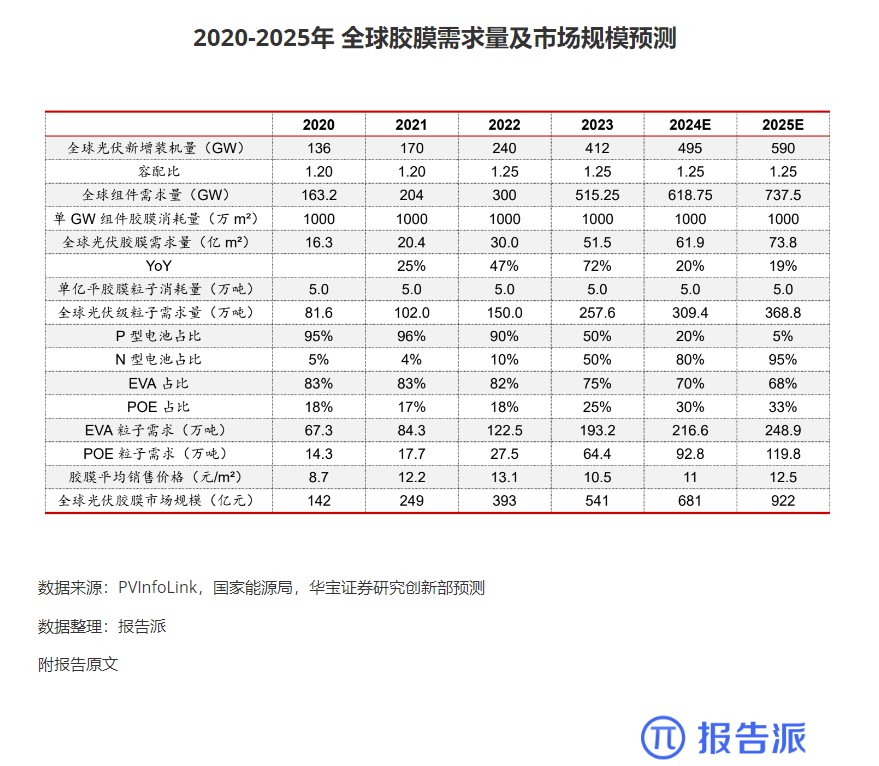
4
2020-2025年 全球胶膜需求量及市场规模预测
市场规模
1874人已阅读
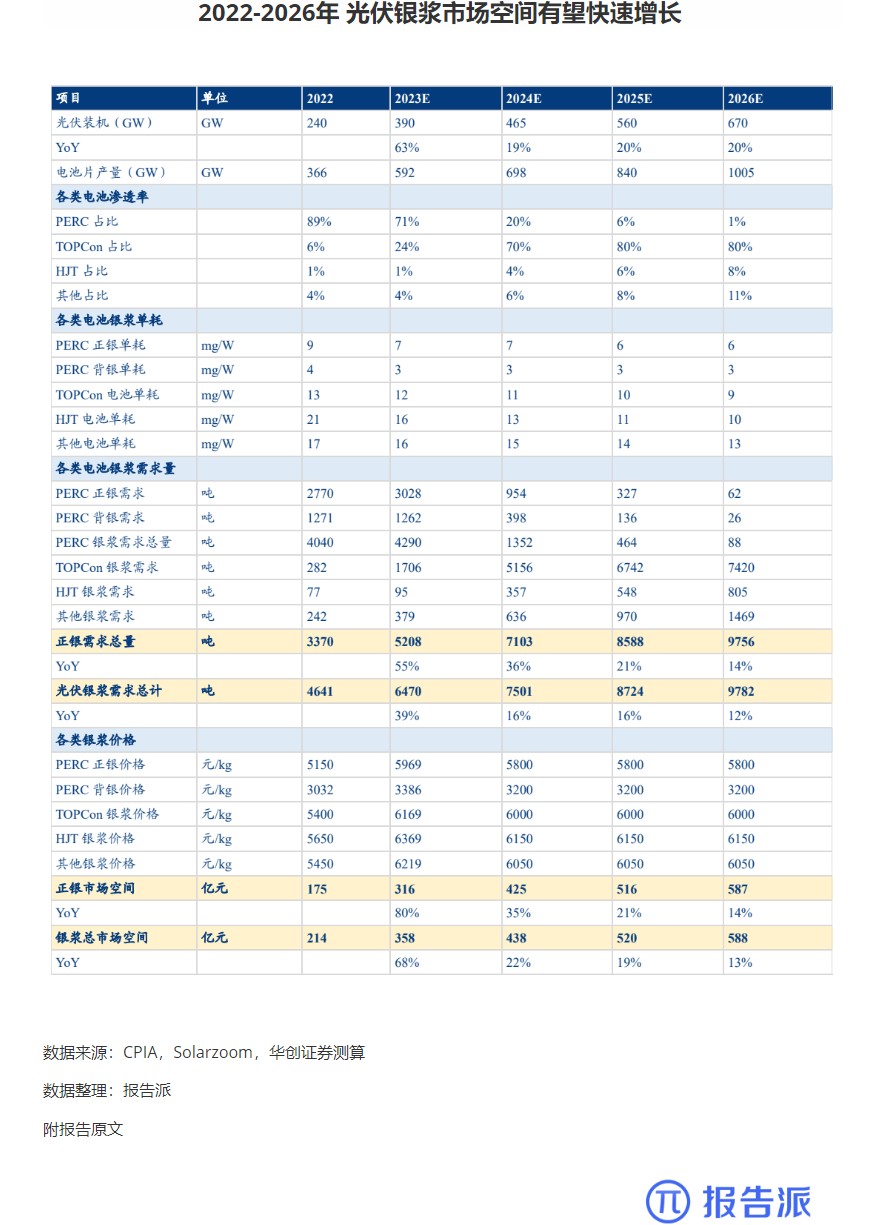
5
2022-2026年 光伏银浆市场空间有望快速增长
市场规模
1943人已阅读
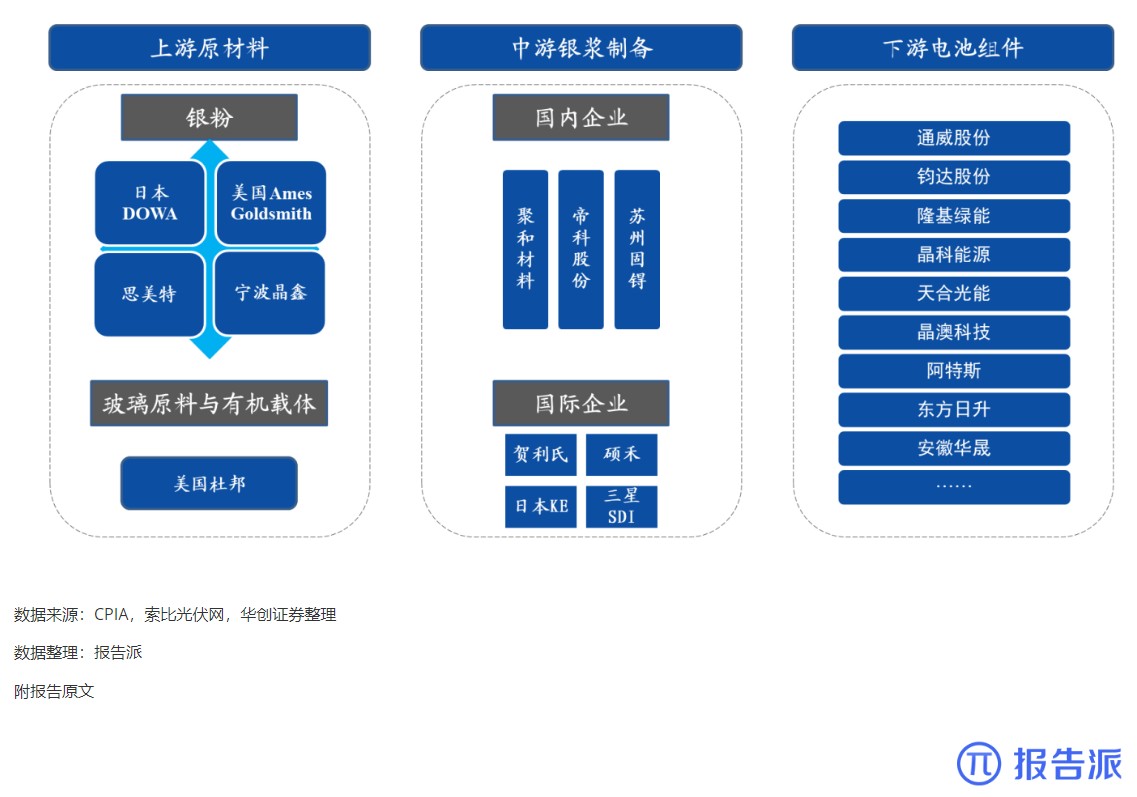
6
光伏银浆产业链相对简单
技术工艺
1838人已阅读
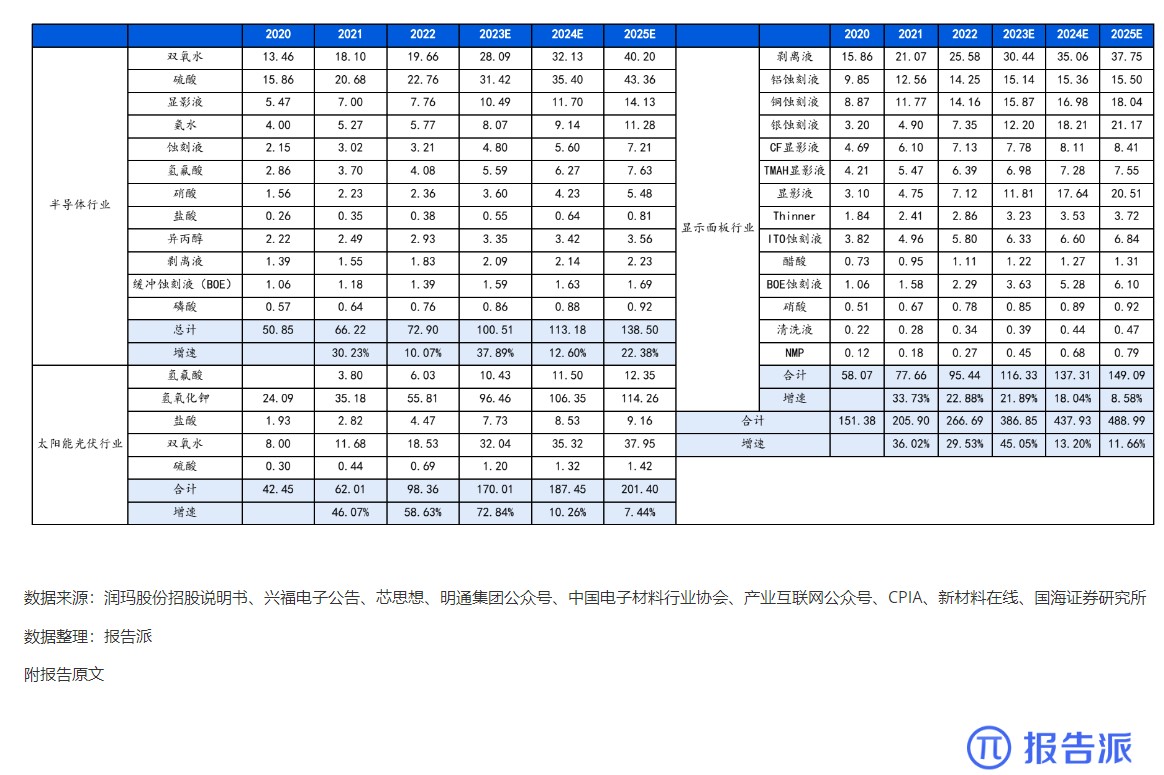
7
2020-2025年 我国湿电子化学品需求预测(万
市场规模
1819人已阅读
8
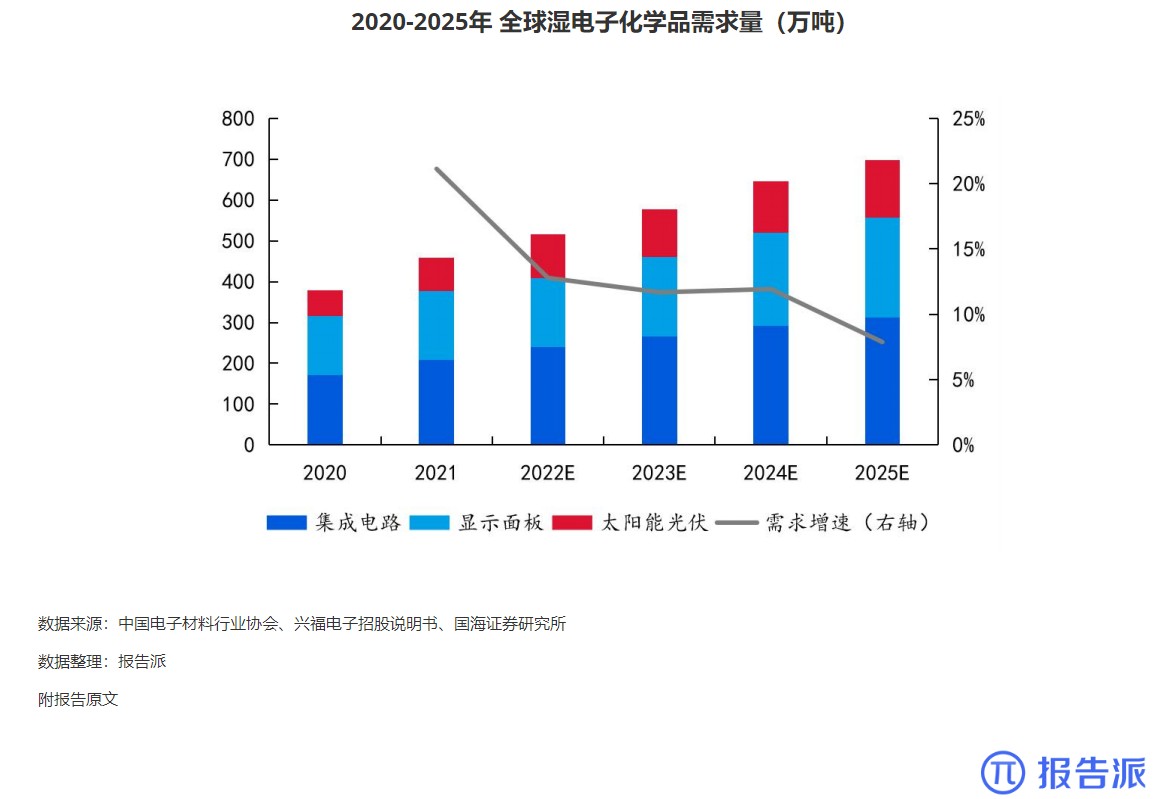
2020-2025年 全球湿电子化学品需求量(万吨
市场规模
1943人已阅读
9
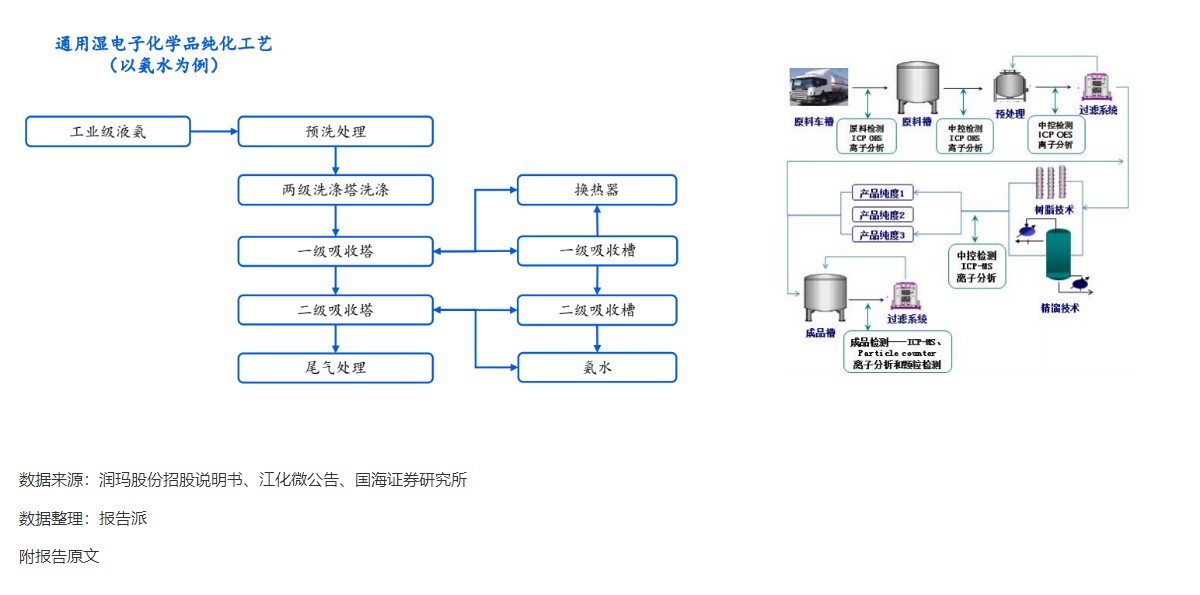
通用湿电子化学品纯化工艺
技术工艺
1685人已阅读
10
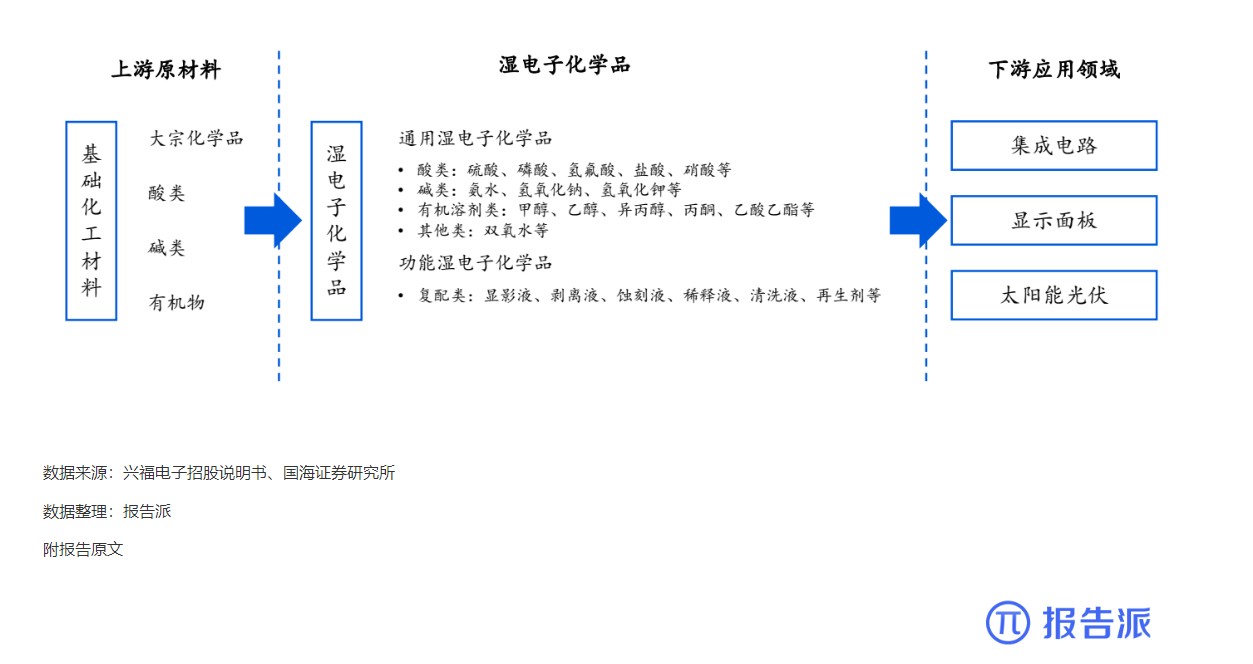
湿电子化学品上下游产业链基本情况
技术工艺
1952人已阅读
热门数据
1
2024年1—2月份规模以上工业增加值增长7.0%
2024-03-22
2
截至2023年底我国累计建成充电基础设施859.
2024-03-22
3
2024年3月21日人民币 NDF 远期合约汇兑美元
2024-03-21
4
2024年1—2月份能源生产情况
2024-03-21
5
2024年2月银行结售汇和银行代客涉外收付款
2024-03-21
6
2024年3月韩国方便面出口2.3万吨,同比增加
2024-03-21



