




报告派研读:2026年大模型发展趋势复盘与展望
摘要: 2026年,大模型技术进入关键演进期。国信证券发布的《大模型发展趋势复盘与展望》深度剖析了过去三年AI叙事的演变路径,并对2026年的产业趋势做出系统性判断。核心观点认为,Scaling Law仍将持续,模型厂商将打开差 ...
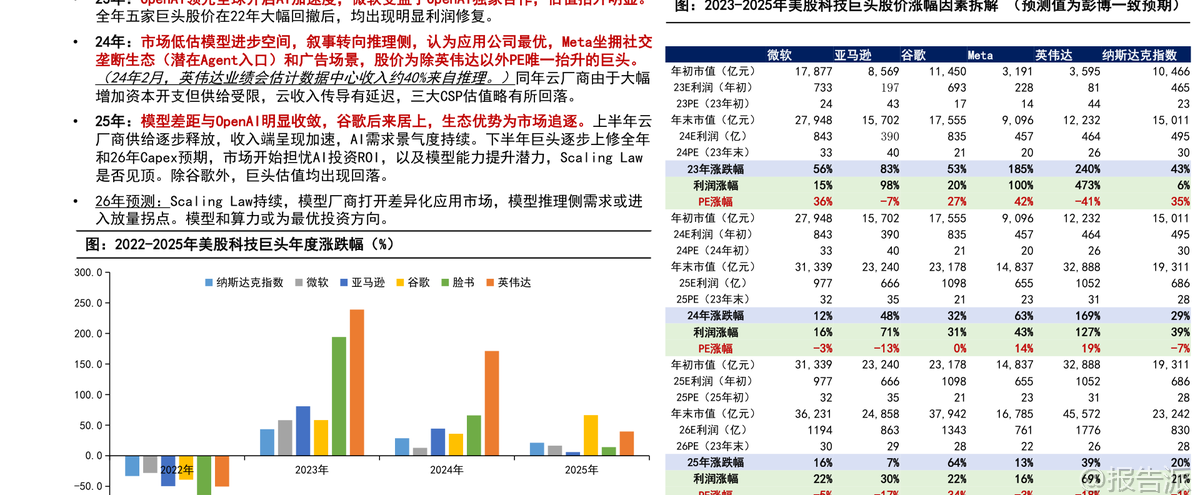
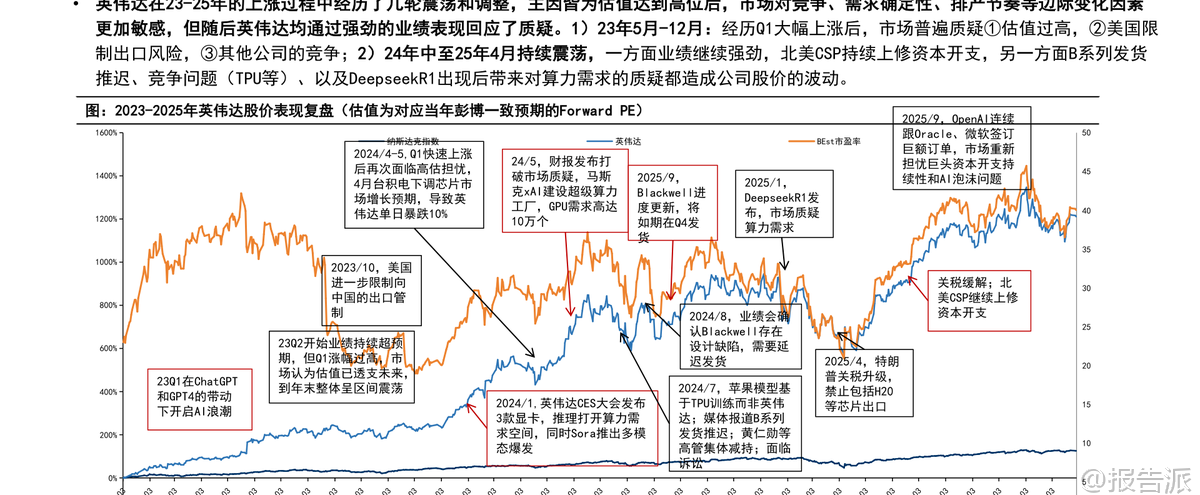
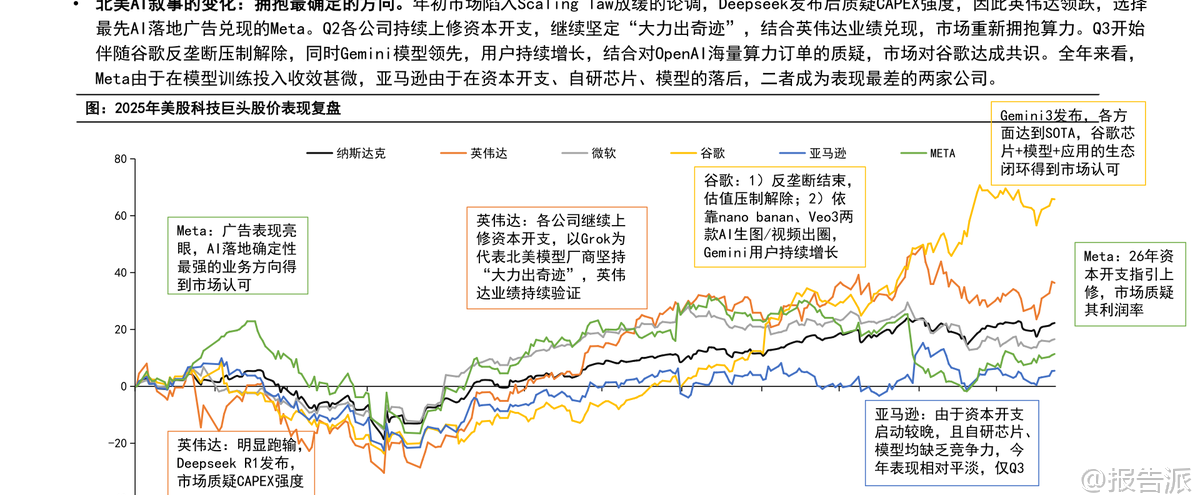
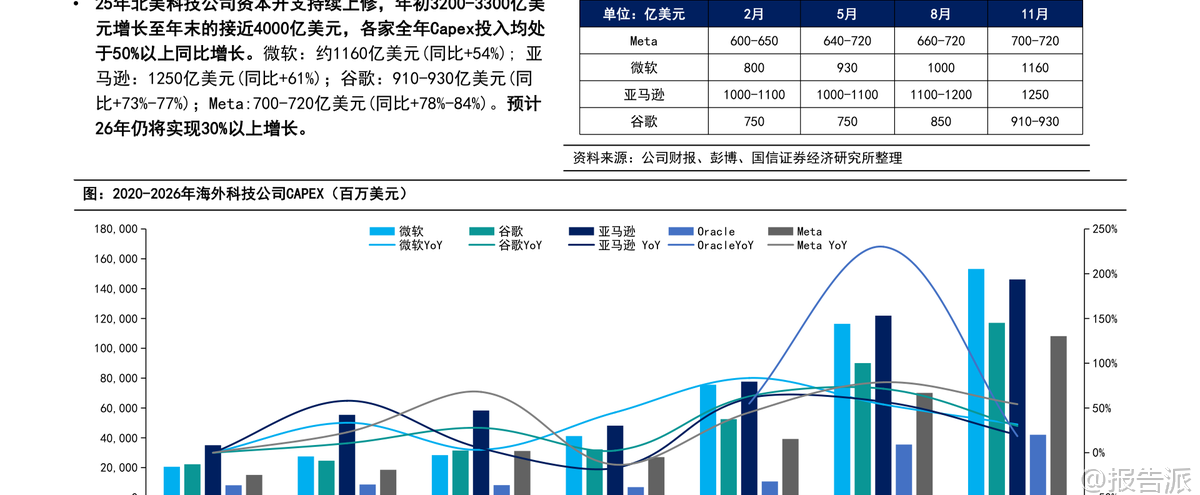
| 2026年,大模型技术进入关键演进期。 国信证券发布的《大模型发展趋势复盘与展望》深度剖析了过去三年AI叙事的演变路径,并对2026年的产业趋势做出系统性判断。 核心观点认为,Scaling Law仍将持续,模型厂商将打开差异化应用市场,推理侧需求有望迎来放量拐点,算力与模型或成最优投资方向。 回顾2023至2025年,美股科技巨头股价走势清晰映射出AI叙事的递进逻辑。 2023年,OpenAI引领全球AI浪潮,微软凭借独家合作估值大幅抬升;2024年,市场低估模型进步空间,转向看好推理侧应用公司,Meta因坐拥社交生态和广告场景成为除英伟达外唯一PE提升的巨头;2025年,谷歌后来居上,Gemini在原生多模态路线上的坚持结合自研芯片与应用闭环生态,使其成为市场追逐的新焦点。 与此同时,北美四家云厂商(微软、亚马逊、谷歌、Meta)资本开支持续攀升,2025年Capex同比增长超50%,全年接近4000亿美元,预计2026年仍将保持30%以上增速。 但电力瓶颈正成为制约扩张的核心因素——据预测,未来五年数据中心将新增80GW用电需求,而电网建设周期长、煤电退役等因素导致电力缺口凸显,推动巨头采取收购能源公司、海外拓展、租赁等方式应对。 在模型架构层面,2026年将迎来后Transformer时代的探索高潮。 当前Transformer架构面临训练阶段计算与内存消耗呈平方级增长、推理时记忆能力有限等瓶颈。 谷歌推出的Titans架构结合Transformer并行优势与RNN线性推理特性,支持动态参数更新和超长上下文(200万+ tokens),实现推理中持续学习。 Mamba架构则采用结构化状态空间模型(SSM),具备线性计算复杂度,在长序列处理上效率更高。 国内厂商如阿里通义千问Qwen3-Next、DeepSeek V3.2则更聚焦成本优化,通过混合注意力机制与稀疏注意力技术显著降低训练与推理开销。 Scaling Law远未见顶。 尽管数据瓶颈显现,但合成数据、架构创新(如Titans)、中训练(Mid-training)等手段仍在延续其生命力。 强化学习成为未来突破重点,尤其是RLVR(基于可验证信号的强化学习)通过让模型自我探索最优思维链,在数学、编程等领域显著提升性能。 DeepSeek提出的GRPO算法进一步优化显存占用,提升训练效率。 多模态与长文本能力成熟为Agent爆发奠定基础。 2025年,行业从“外挂式多模态”转向“原生多模态”,Gemini、GPT-4o、Qwen3-Omni等模型实现统一token表示不同模态内容的技术突破。 长文本处理能力也大幅提升,部分模型支持百万级上下文,使Agent能在复杂任务中保持记忆连贯性。 这使得AI Agent从概念走向实用,在编程、办公、搜索等场景快速落地。 商业化格局呈现分化。 OpenAI虽短期被反超,但8亿C端用户构成核心壁垒,2026年将发力企业业务;Gemini凭借技术积累与高质量数据(搜索+YouTube)成为SOTA基准,Tokens消耗持续高增;Anthropic坚持2B路线,在编程领域建立绝对优势,ARR已达10亿美元,估值达3500亿美元;xAI则信奉“大力出奇迹”,依托特斯拉独特数据与巨额算力投入,下一代Grok5值得期待。 推理需求正在爆发。 2025年tokens消耗主要来自大模型厂商内部重构,2026年起下游应用需求将加速释放。 一级市场已涌现多个爆款:Cursor(AI编程)ARR达10亿美元,Manus(通用Agent)上线8个月ARR破亿,Perplexity(AI搜索)ARR逼近2亿。 AI手机助手、AI眼镜等端侧场景也在加速落地,预计2026年全球AI眼镜出货量将达千万台级。 长期来看,大模型正重构软件产业。 IDC预测2029年全球SaaS市场规模将达近万亿美元,但玩家将重新洗牌。 通用型、低准确度要求的工具易被替代,而拥有数据壁垒、流程复杂或高精度需求的垂直领域(医疗、能源、会计等)风险较小。 同时,大模型厂商正与传统SaaS企业展开合作或竞争,推动分销商、咨询服务商(如IBM、埃森哲)需求上升。 投资建议方面,推荐关注算力基础设施(英伟达、阿里、百度、谷歌)及大模型厂商(阿里、腾讯、谷歌)。 风险提示包括宏观经济波动、需求不及预期、技术升级不及预期及AI平权带来的云业务利润率压力。 本文由【报告派】研读,输出观点仅作为行业分析! 原文标题:原文标题:2026-01-05-国信证券-国信证券-人工智能行业专题(14):大模型发展趋势复盘与展望 发布时间:2026年 报告出品方:国信证券 文档页数:47页
精品报告来源:报告派 |
推荐文章

2
2025年中国人幸福感研究报告
资讯
23人已阅读

3
2025年基于CXL方案的AI应用研究
资讯
16人已阅读

4
2025年药物政策发展维度报告
资讯
27人已阅读

5
2025年人形机器人产业发展报告
资讯
39人已阅读

6
2025年中国钢铁行业转型金融报告
资讯
29人已阅读

7
2025年中国社保体系改革前瞻报告
资讯
23人已阅读

8
2025年欧盟全球地位观察报告
资讯
30人已阅读

9
2025年混合云网络安全韧性白皮书
资讯
27人已阅读

10
2025年网页到应用转化路径研究报告
资讯
31人已阅读
数据图表
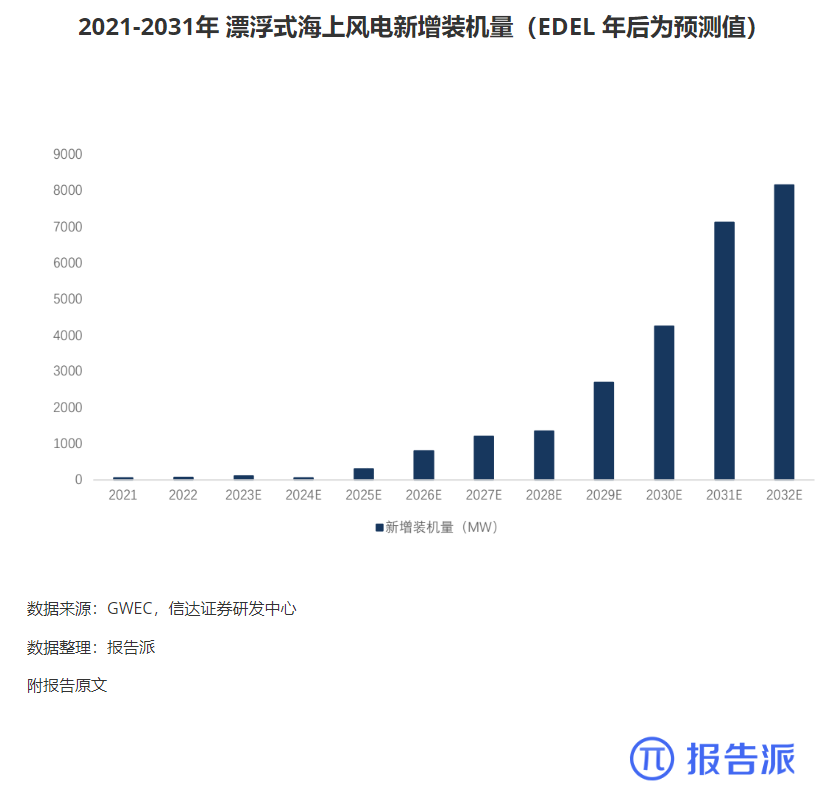

2
2011-2031 年全球海上风电装机量(含预测)
行业数据
1656人已阅读
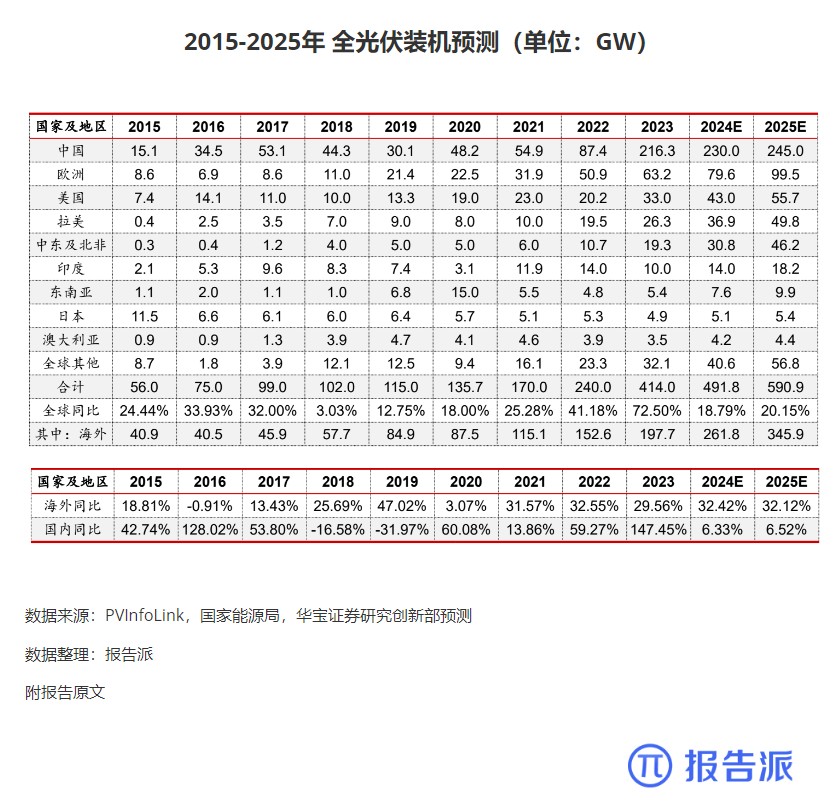
3
2015-2025年 全光伏装机预测(单位:GW)
市场规模
1876人已阅读
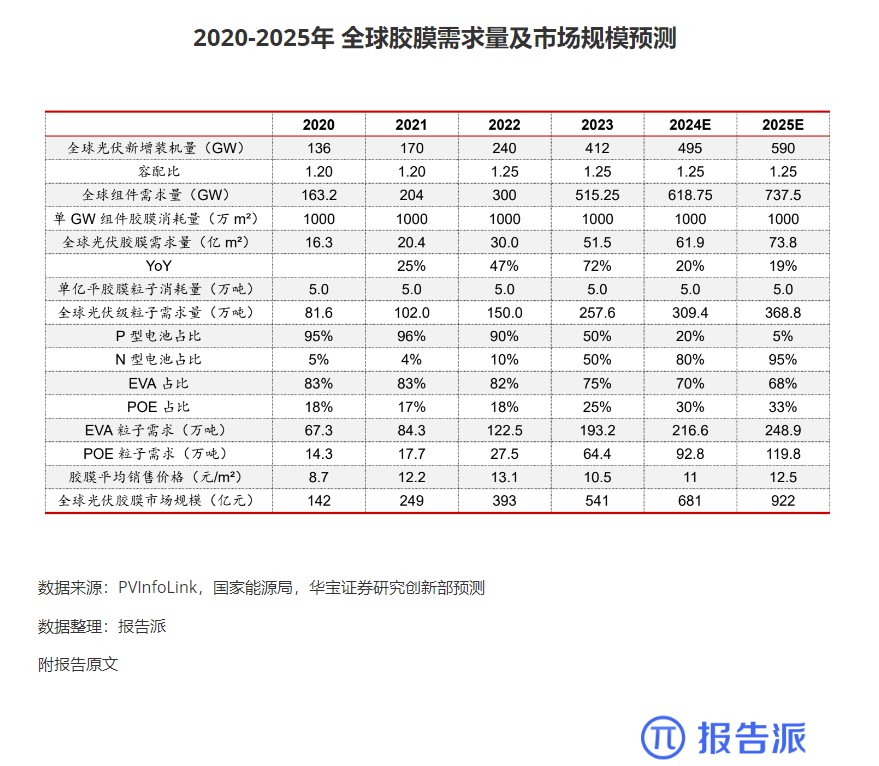
4
2020-2025年 全球胶膜需求量及市场规模预测
市场规模
1800人已阅读
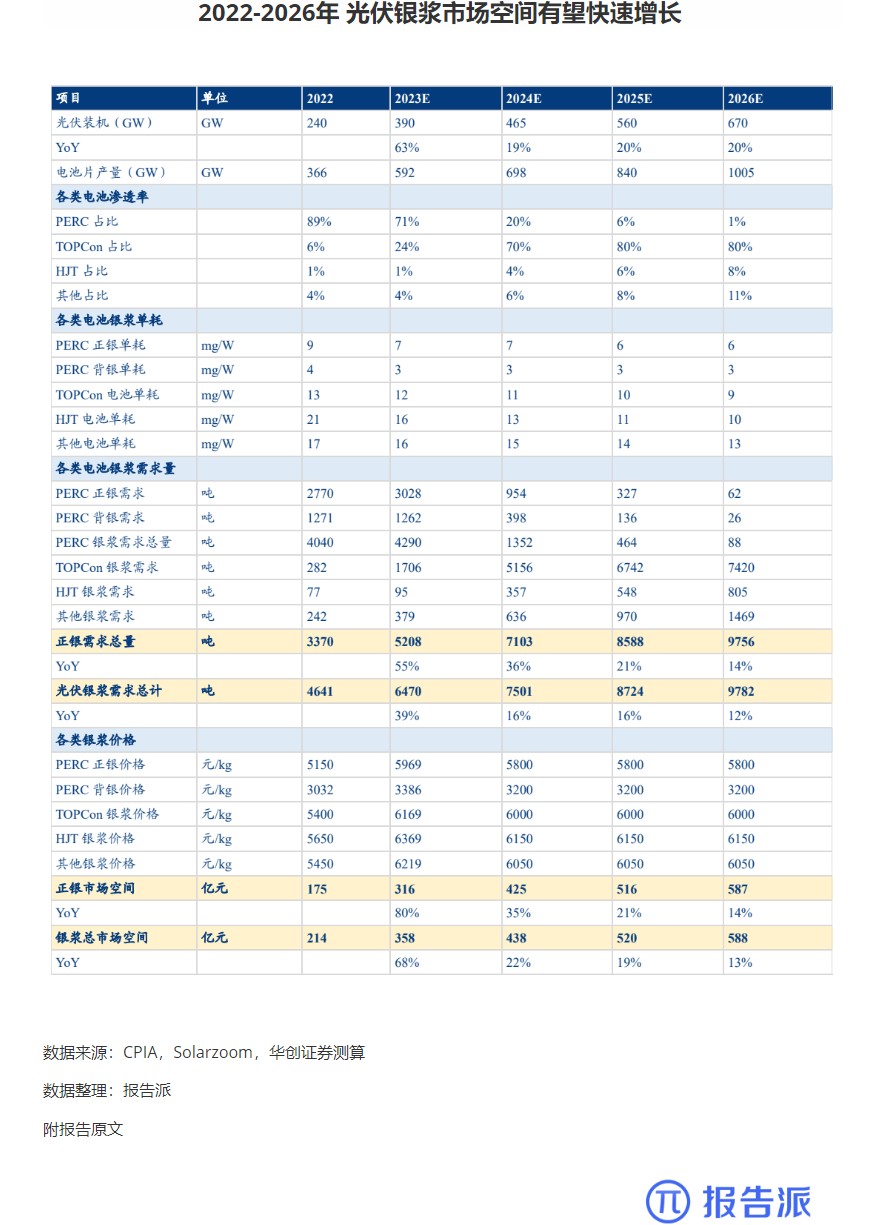
5
2022-2026年 光伏银浆市场空间有望快速增长
市场规模
1862人已阅读
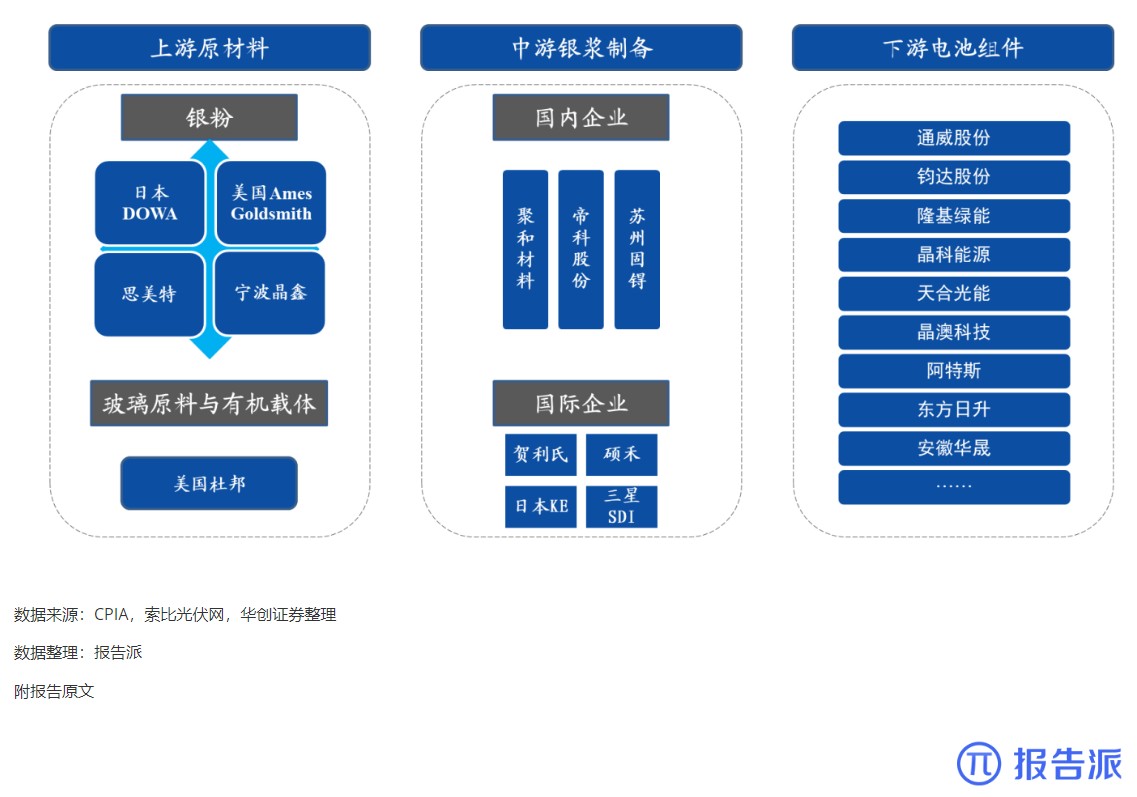
6
光伏银浆产业链相对简单
技术工艺
1763人已阅读
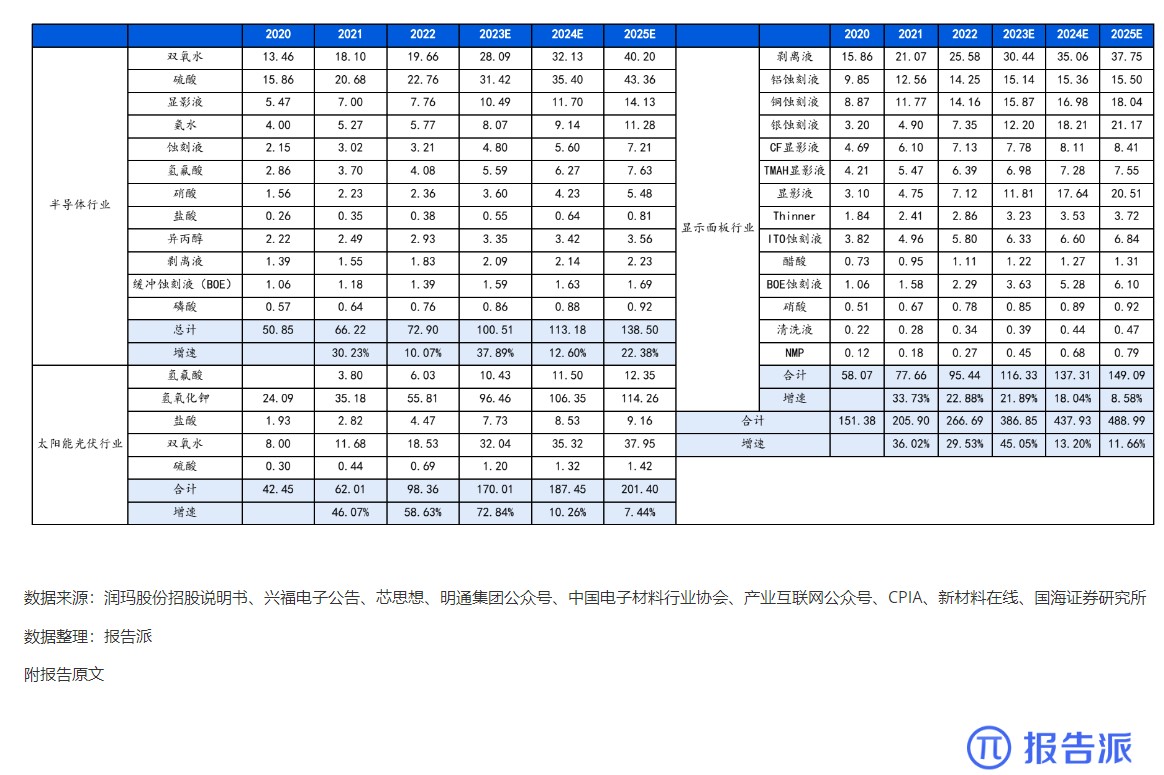
7
2020-2025年 我国湿电子化学品需求预测(万
市场规模
1747人已阅读
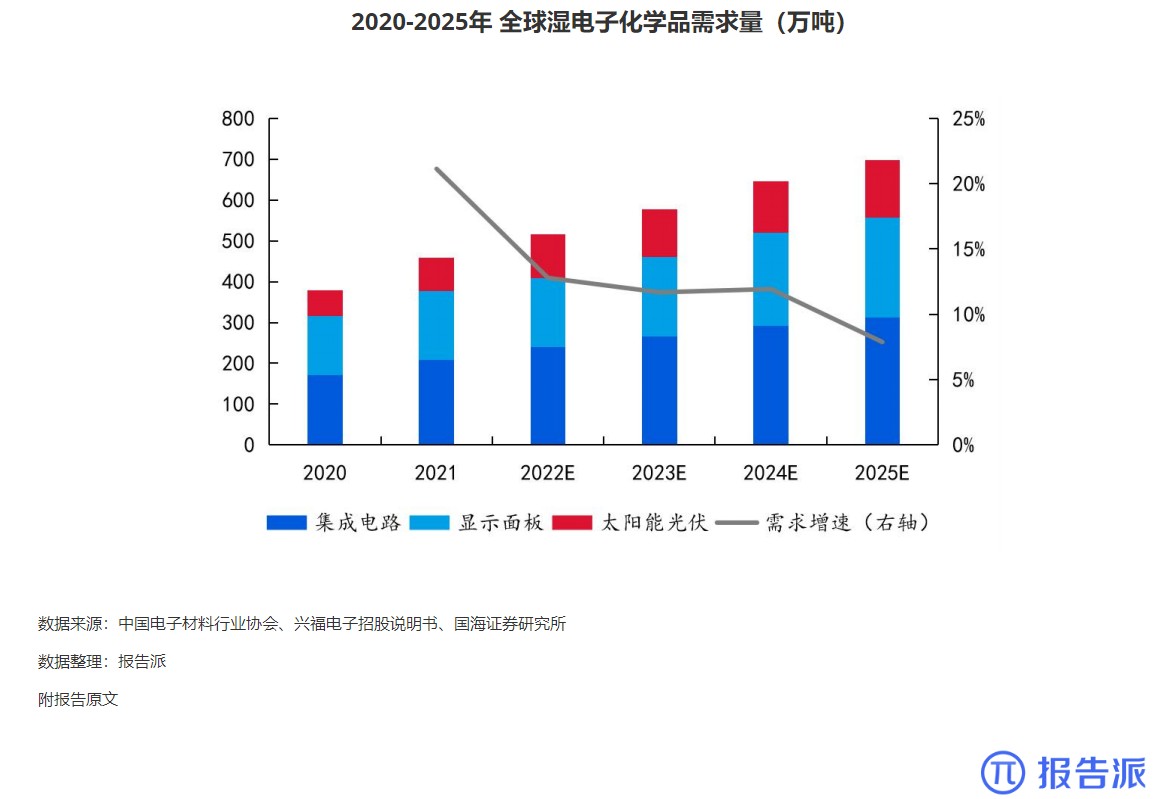
8
2020-2025年 全球湿电子化学品需求量(万吨
市场规模
1876人已阅读
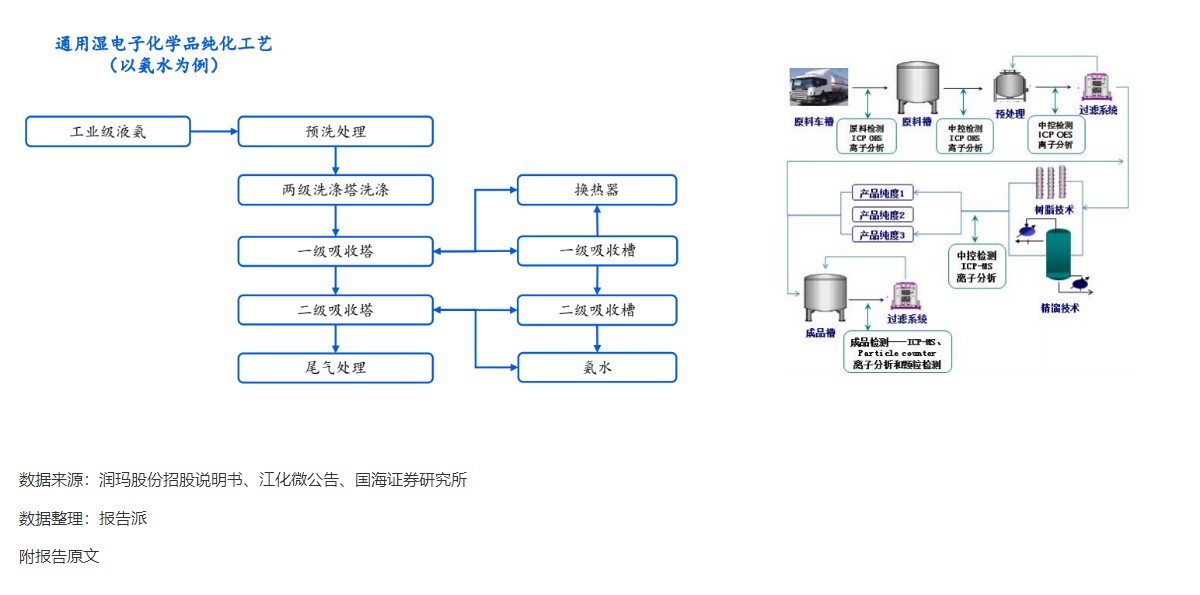
9
通用湿电子化学品纯化工艺
技术工艺
1613人已阅读
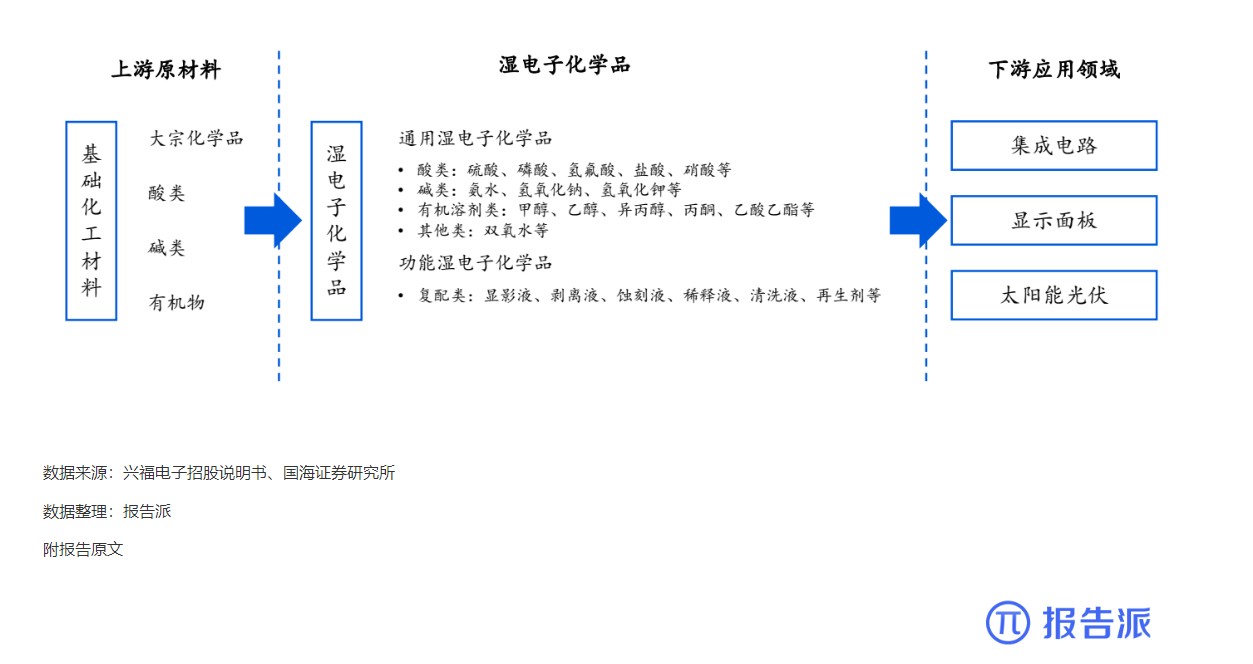
10
湿电子化学品上下游产业链基本情况
技术工艺
1887人已阅读
热门数据
1
2024年1—2月份规模以上工业增加值增长7.0%
2024-03-22
2
截至2023年底我国累计建成充电基础设施859.
2024-03-22
3
2024年3月21日人民币 NDF 远期合约汇兑美元
2024-03-21
4
2024年1—2月份能源生产情况
2024-03-21
5
2024年2月银行结售汇和银行代客涉外收付款
2024-03-21
6
2024年3月韩国方便面出口2.3万吨,同比增加
2024-03-21



